
PC에서 다루기에 데이터가 커지면, 즉 대략 몇 GB정도를 넘어가면 작업 속도가 현저히 떨어지기 시작한다. 속성값을 필터링하고 group by 해서 집계해보는데도 몇 초 정도는 걸리며, 혹은 그 결과물을 서로 비교하는 그래프를 그리는데도 적지 않은 노력이 든다.
많은 양의 데이터를 탐색할 때는 생각의 끊김 없이 데이터를 헤집어볼 수 있는게 중요한데, 속성을 덜어내거나 더할 때, 혹은 날짜를 바꿔가면서 값들을 비교해볼때, 시군구 단위처럼 넓은 지역의 집계량을 비교해볼 때 실시간으로 결과물을 확인할 수 있다면 데이터가 가진 특성을 빠른 시간안에 이해할 수 있고 문제점 혹은 특별한 현상을 발견하기가 매우 용이해진다.
데이터 필터링에서 시각화로 이어지는 반복되는 작업들을, 현대의 빠른 PC성능을 최대한 활용해서 반응형으로 구현하고자 했던게 그동안 지속적으로 시도해왔던 작업들이고, 올해 했던 작업 중 하나는 그런 부분적인 시도들을 종합해서 하나의 결과물로 만들어 보는 일이었다. 토지주택연구원 쇠퇴지역재생역량강화연구단으로부터 의뢰를 받아 통신사의 유동인구와 카드사의 매출액 데이터 뷰어(viewer)를 만들었는데, 그 결과물을 일부 소개해보려고 한다.
작업은 늘 그렇듯 C++ 기반으로 OpenGL라이브러리를 이용했다.
데이터는 3종류였다.
1) 50m 그리드의 일별/성연령별 유동인구
2) 50m 그리드의 시간대별 유동인구
3) 소지역 단위 일별/성연령별/항목별 매출액
데이터의 크기는 지역에 따라 다른데, 서울 같은 경우 일별 데이터의 한달치가 c++에서 아래처럼 구조체를 만들어 바이너리 형식으로 저장하면 약 300MB 전후가 된다.
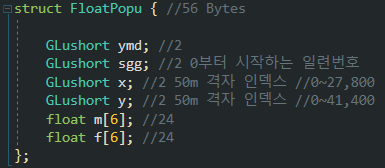
프로그램을 띄울때마다 텍스트 형식의 데이터를 읽게 되면 텍스트를 정수나 실수 등의 형식으로 parsing하는데 시간이 너무 많이 걸린다. 바이너리를 만들어두면 SSD가 허용하는 읽기 속도의 절반 정도로 데이터를 읽어들일 수 있다.
pc에서 다루기에는 데이터가 크다면 큰 편이다. 그래서 되도록이면 데이터값 하나마다 4Byte(32bit) 변수를 온전히 쓰지 않고 16bit나 8bit, 혹은 1bit 단위로 쪼개서 관리해야 한다. 용량도 줄어들고 처리속도도 당연히 빨라진다.
읍면동 같은 경우 전국이 3500개 내외이므로 0~65535 범위인 16bit 변수에 충분히 넣을 수 있다. 50m 그리드 단위의 유동인구 위치 역시, 미터 단위의 전 국토 범위를 50으로 나누어 관리하면 xy좌표 각각을 16bit 변수로 관리할 수 있다.
인구 값은 raw 데이터 자체의 유효 숫자가 4자리 내외이므로 충분히 32비트 부동소수점 범위로 표현할 수 있다. 단 집계할 때는 64bit로 관리해야 많은 양을 더할 경우 값을 잃지 않게 된다.
결과물의 화면은 아래와 같다.
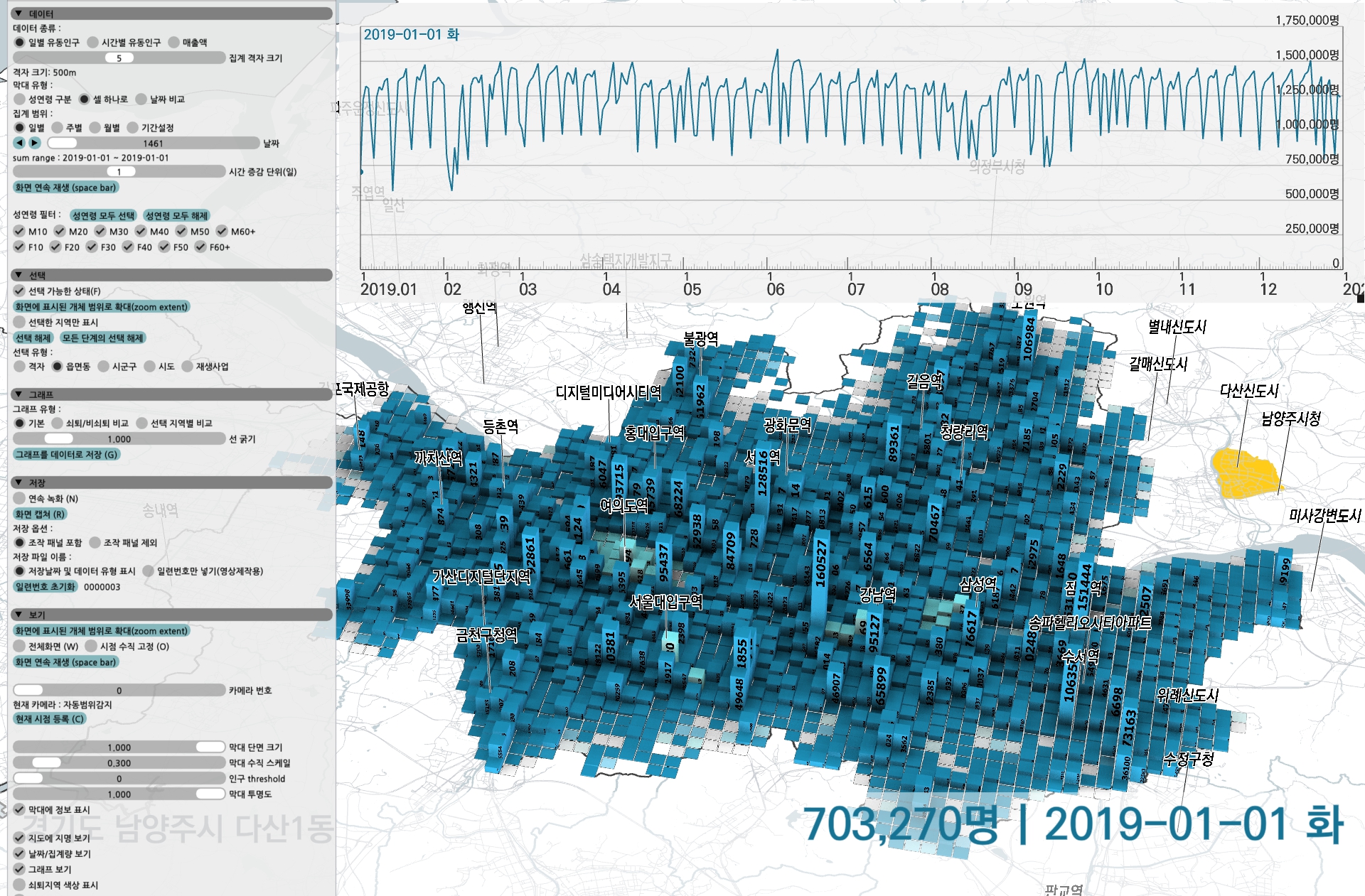
zoom 과 pan이 가능한 전국 지도가 배경에 깔리고 특정 지역을 선택한 집계 값을 볼 수 있는 선형 그래프, 그리고 여러가지 옵션을 바꿔볼 수 있는 조작패널이 있다.
조작패널은 Imgui 라이브러리를 사용했는데, UX는 크게 신경쓰지 못한 탓에 기본적인 조절자들이 다소 거칠게 구현되어 있다.
일별 유동인구의 경우 하나의 그리드는 아래처럼 12개의 성연령별 단위로 쪼개져서 출력된다.
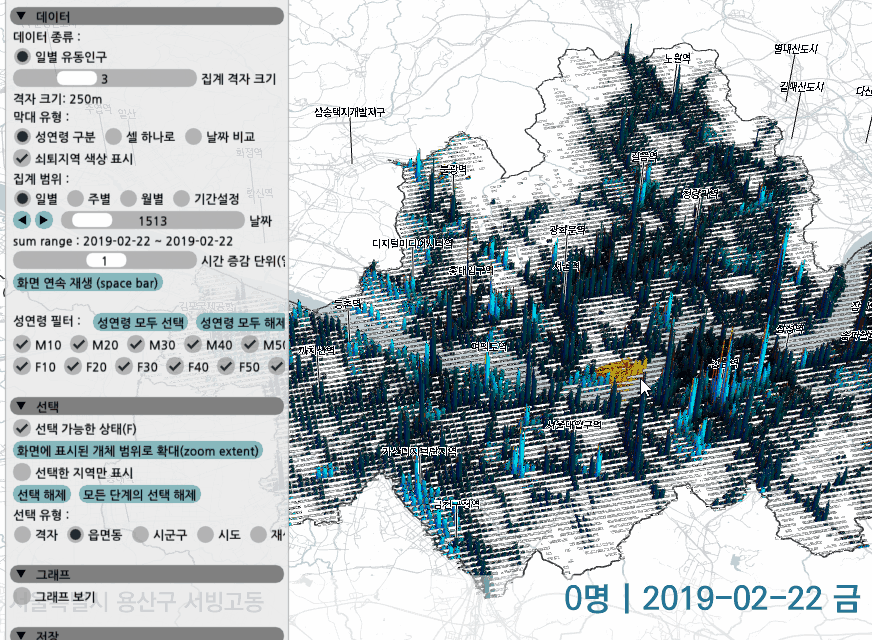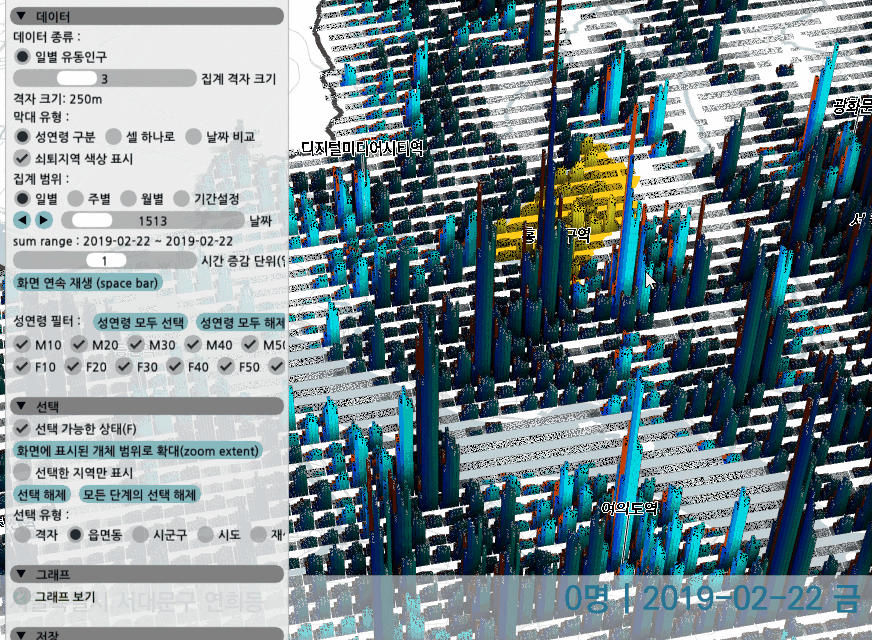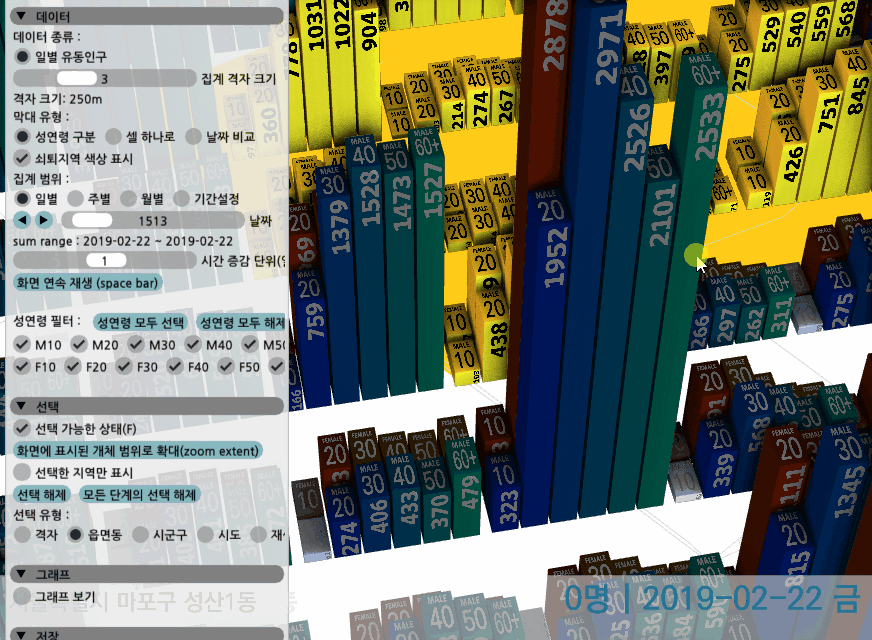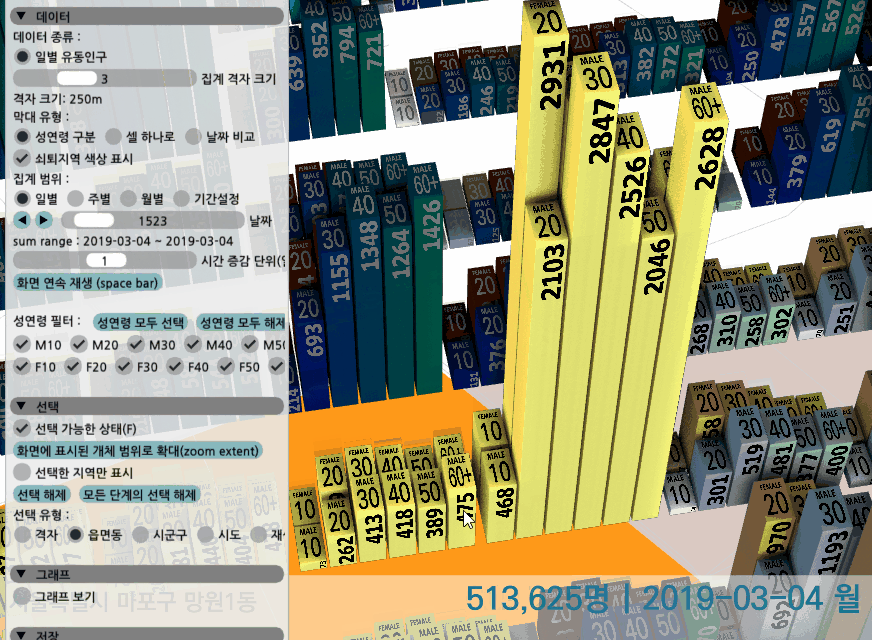
zoom/pan을 해가면서 특정 지역을 선택할 수 있고, 날짜를 바꿔보면서 변화를 확인할 수 있다.

하나의 셀은 성연령으로 구분하거나, 그냥 막대 하나로 성연령 구분없이 합쳐볼 수 있다. 혹은 두 날짜를 선택해 값을 비교하고, 우세한 날짜의 색상이 더 잘 보이도록 막대를 표현할 수 있다.
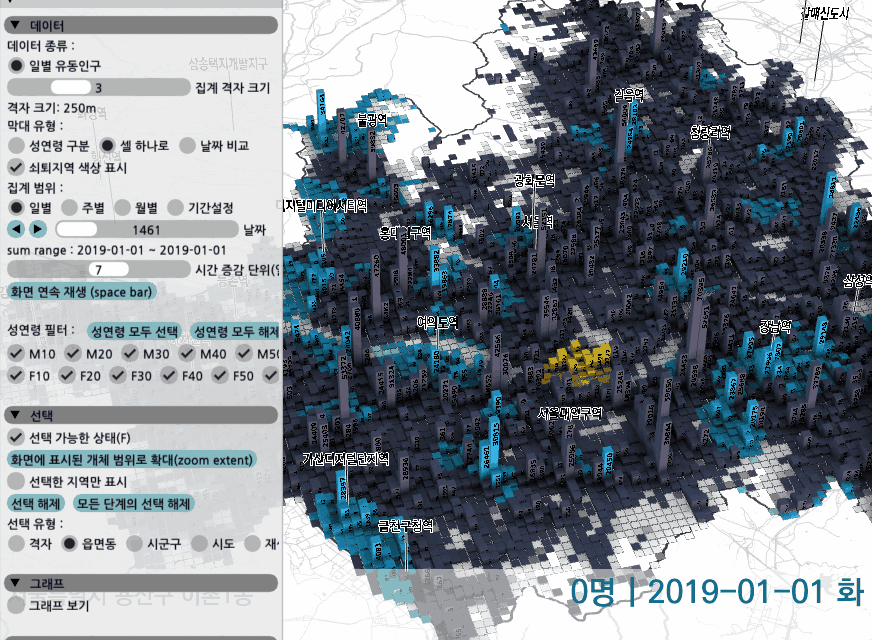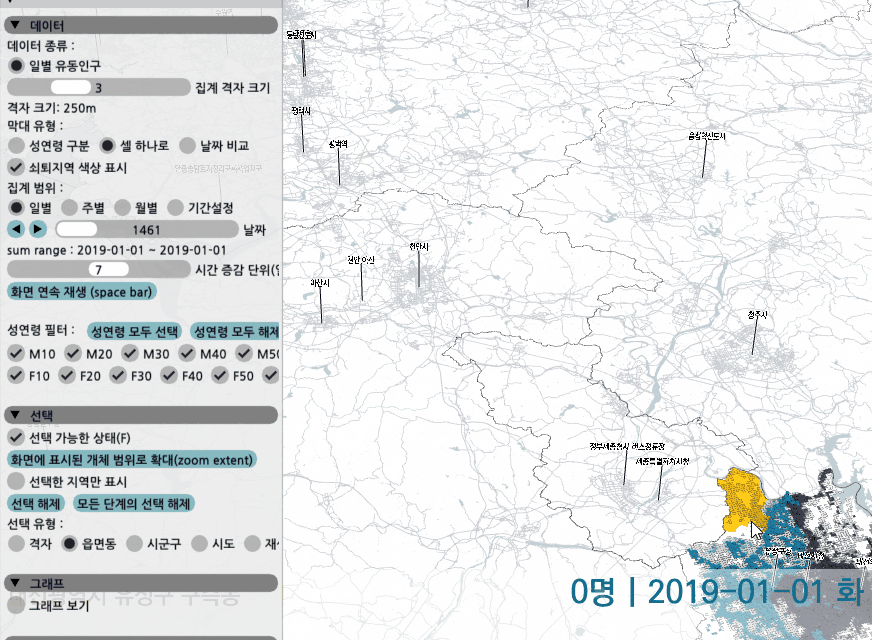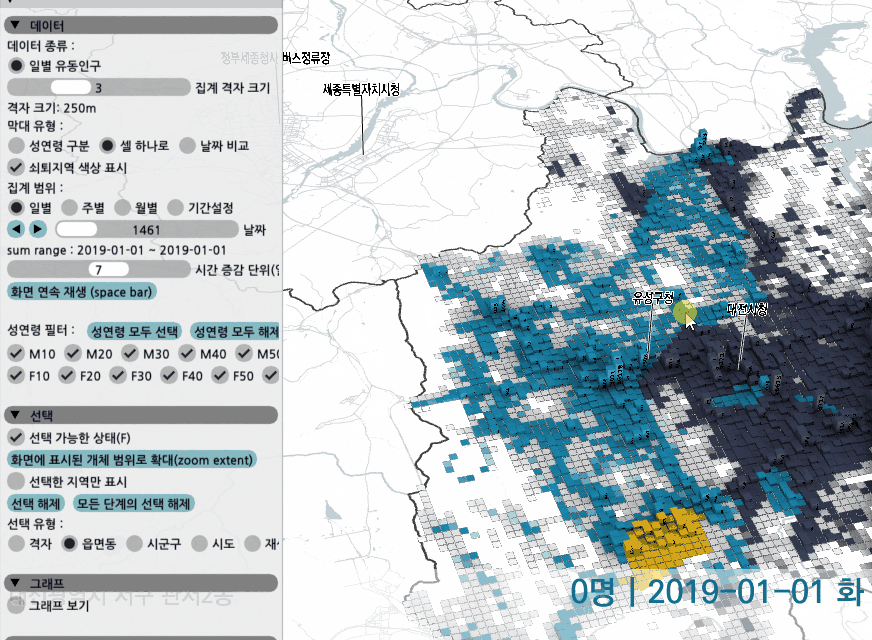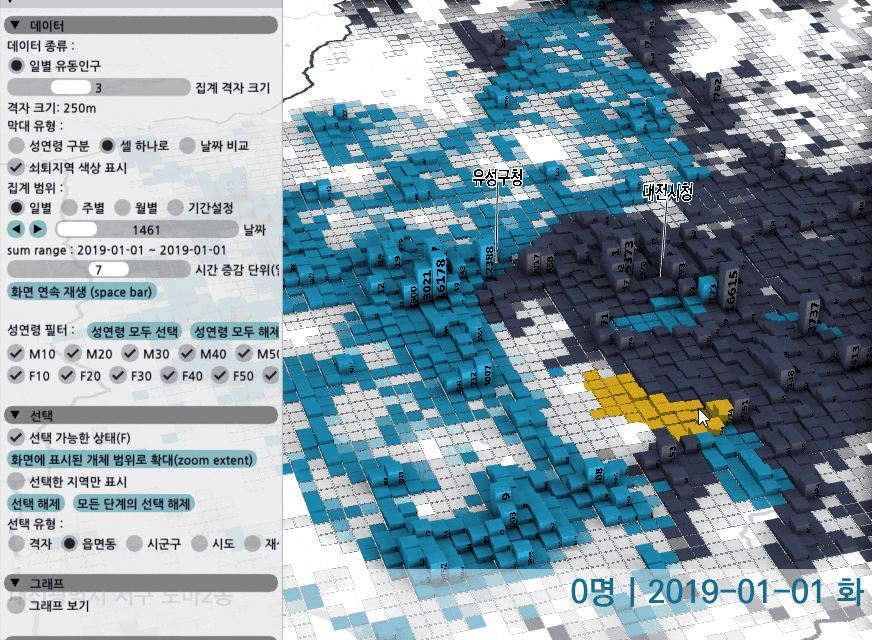
화면에서 돌아가는 데이터는 서울과 대전의 26개월치 일별 유동인구 데이터로, VRAM에 올라간 용량 기준으로 약 11GB정도 된다. 24GB의 RTX3090 이라면 더 많은 데이터를 올려서 30fps 이상으로 조작해볼 수 있다.

기본적으로 50m 단위의 데이터들을 50, 100, 200, 250m ~ 10km 그리드 등 11단계의 정해진 그리드 단위로 집계해볼 수 있다. 처음에는 별도의 정해진 snap 없이 50m 단위로 바꿔볼 수 있도록 했었지만, 퍼포먼스를 위해 소속 시군구 코드 등 몇가지 정보들이 미리 입력된 11단계 그리드를 준비하여 사용하게 되었다. 물론 날짜별로 다른 값의 데이터들을 모두 미리 집계할 수는 없으므로 집계는 GPU에서 옵션을 바꿀때마다 실시간으로 이루어진다.

성연령값을 필터링하면 화면에 바로바로 집계된 값들이 바뀌어 나타나게 된다.

그리드 하나하나씩 선택해서 시계열로 집계해볼 수 있으며, 읍면동, 시군구, 시도 단위 전체까지 끊김 없이 집계가 가능하다. 즉 5GB 이상의 데이터를 GPU에서 atomic 연산으로 집계하기 때문에 소요시간을 못 느낄 정도로 빠르게 합산된다. OpenGL 셰이더인 glsl 기준으로, NVIDIA 그래픽 카드에서는 64bit 변수의 atomic 연산을 지원하는데, 일반 RTX 시리즈의 경우 64bit 연산 속도는 그리 높지 않아 약간 우려하긴 했지만 의외로 빠르게 계산해주었다.

서울과 대전 전체를 선택해서 두 도시 특정 날짜의 유동인구 총량의 변화를 볼 수 있다. 옵션을 바꾸면 쇠퇴지역/비쇠퇴지역 등 지역에 따라 미리 구분된 속성에 따라 데이터를 별도로 집계해서 비교해 볼 수도 있고, 두 지역을 분리해서 합산해볼 수도 있다. 서울과 대전의 유동인구 총량이야 위 그림처럼 매우 크게 차이나므로 별로 비교할 필요가 없겠지만, 같은 도시 안에서 시군구나 읍면동의 비교 기능은 유용하게 쓰일 수 있다.
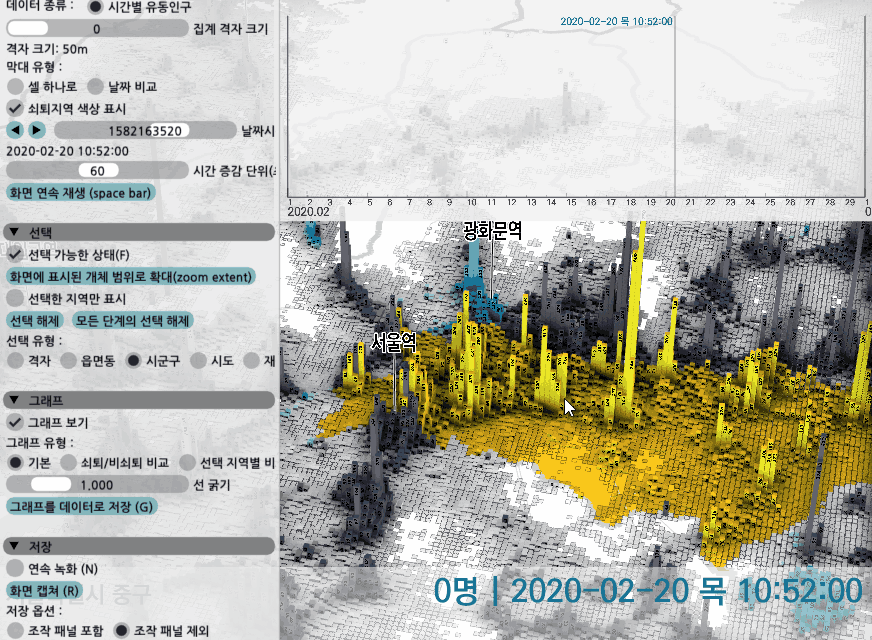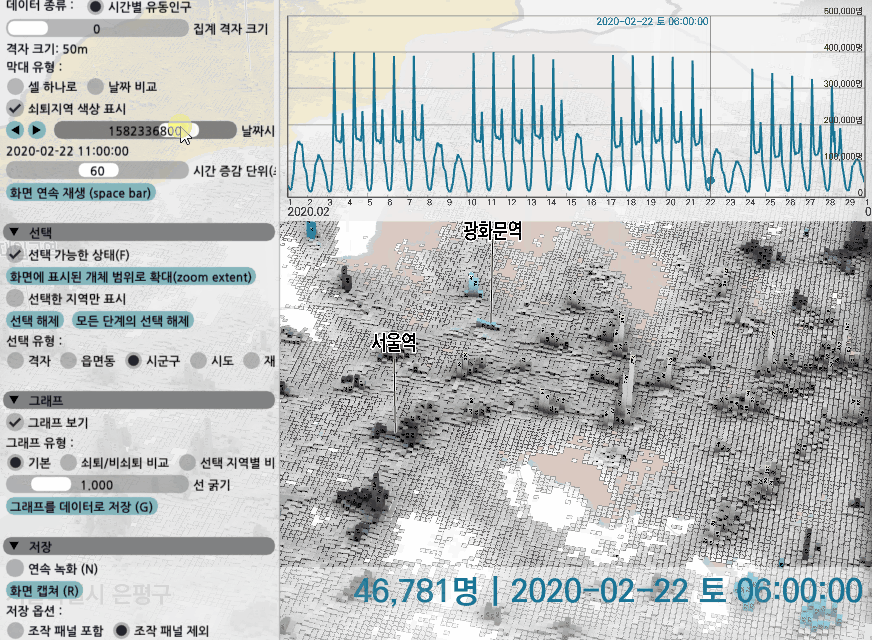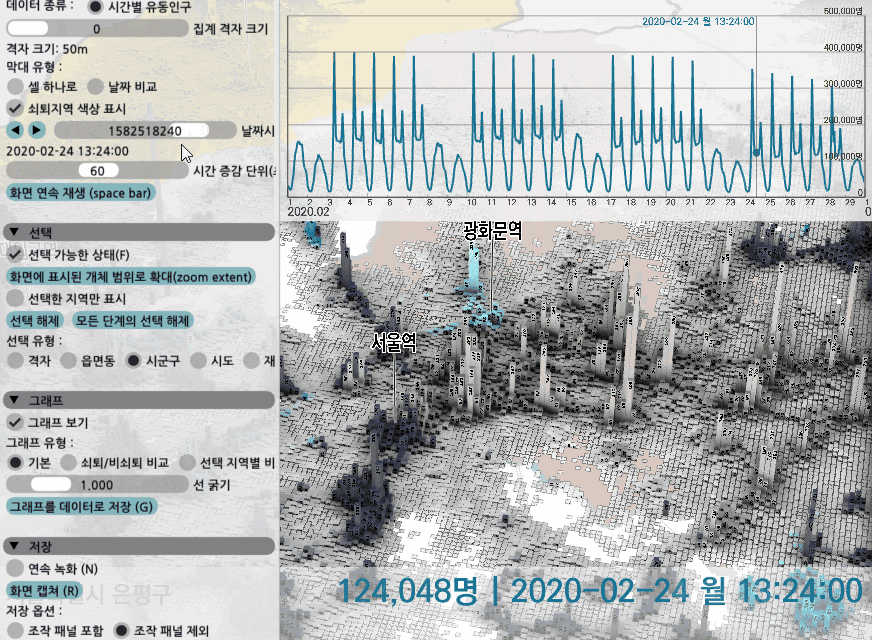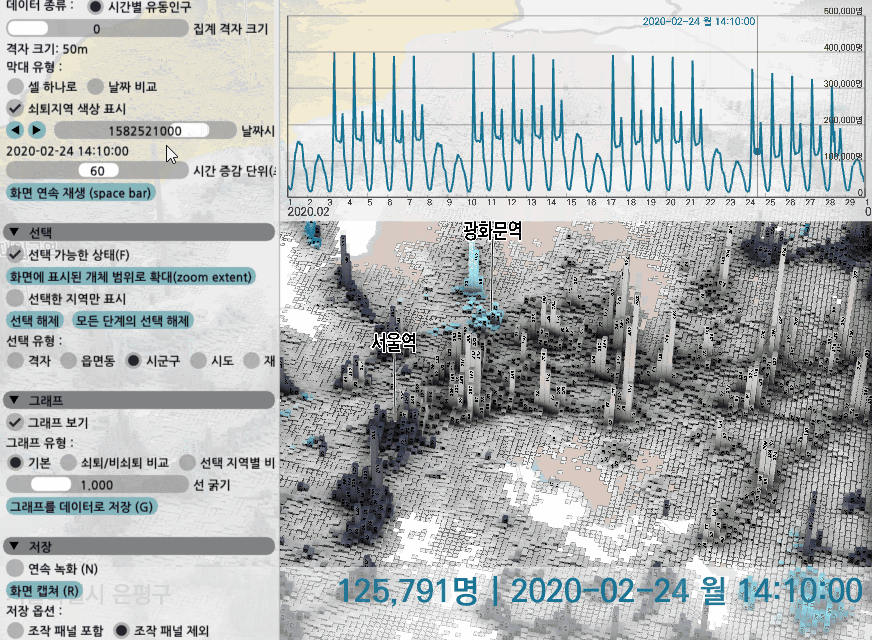
시간대별 유동인구의 경우 데이터가 시간 단위로 있는데, 몇시 몇분처럼 그 사이의 특정 시각일 경우 두 시점의 데이터를 읽은 후 선형 보간을 해서 그 변화 양상을 관찰할 수 있도록 해봤다. 시각 조절자를 드래그하거나 '재생' 키를 눌러 변화 양상을 볼 수도 있다.
가장 고민했던건 화면 안에 존재하는 개체들인 막대, 행정구역 경계, 그래프 사이에 데이터가 끊김없이 흐르도록 하는 과정이었다. 사용자 입력 직후 약간의 처리를 한 다음에는 모든 내용이 GPU안에서 흘러다녀야 했는데, 그러기 위해 아래와 같은 데이터 형식과 상호 연관 구조를 만들어봤다.

16bit 단위의 gridInfo 변수는 전 국토를 해당 그리드로 나눈 만큼의 양으로 미리 준비했다. 즉, 50m 그리드는 동서 방향으로 27,000개, 남북방향으로 41,400개 있으므로 전 국토 기준으로 27000 x 41400 x 2Byte = 약 2GB의 공간을 미리 준비해야 한다. 100m 그리드에는 500MB가 필요하고 200m 그리드에는 125MB가 필요하다. 11단계 다 해서 대략 최대로 VRAM 4GB정도를 기본으로 차지하게 된다.
물론 전 국토인 경우 이처럼 많이 필요하지만, 읽어들인 데이터의 동서남북 최대최소치를 읽어 해당 공간에만 미리 그리드를 준비하면 되므로 실제 준비 공간은 많이 줄어든다. 전국을 모두 올리거나 백령도, 울릉도, 제주도, 강원고성의 데이터를 한꺼번에만 올리지 않는다면.
이 처리 방식을 알고리즘이라고 부를 수는 없지만, 흔히 메모리를 많이 차지하는 방식과 그렇지 않은 처리 방식 사이에서 저울질하는 경우가 종종 있다. 일단 이 방식은 메모리를 최대한 차지하는 방식이므로 개선의 여지가 있는지는 좀 더 생각해봐야 할 것 같다.
그래서 16bit 각각에는 몇 가지 const 값들을 넣는다.
읍면동은 전국에 3500여개가 있으므로 일련번호를 붙여서 관리하면 12bit 범위 안에서 표현할 수 있다. 나머지 4개의 비트에는 쇠퇴지역이나 재생사업지역 등 속성을 부여한 특정 지역에 대한 정보를 넣어놓을 수 있다.

읍면동 코드는 위처럼 관리하는게 좋다. 시군구나 시도 역시 읍면동 일련번호와 똑같은 수 만큼 발생시켜둔다. 4번 읍면동이 어떤 시군구에 속하고 다시 어떤 시도에 속하는지 알아보려면 시군구 배열의 4번째 변수, 시도 배열의 4번째 변수를 조회하면 된다.
물론 원래 읍면동 코드는 42030120 처럼 [시도코드 42] + [시군구코드 030] + [읍면동코드 120] 처럼 시도와 시군구 정보를 모두 담고 있지만 이렇게 8자리 숫자를 온전히 사용하기에는 저장공간의 문제나 배열 방식으로 빠르게 접근할 수 없다는 문제가 있으므로 0,1,2,3 에 해당하는 일련번호로 다시 바꾸는 작업이 필수적이다.
데이터 흐름의 핵심은 아래 그림에 모두 들어 있다.
예를 들어 종로구 경계 안에서 마우스를 클릭하면, 종로구가 노랗게 선택되어야 하고, 종로구 안의 그리드들이 모두 선택되어야 하고, 그 선택된 그리드의 선택 날짜 데이터들이 지도 밑에 합산되어 표현되는 동시에 그래프에는 데이터가 입력된 전체 시간 범위만큼 집계되어 표현되어야 한다.
사실, 그게 가장 간단한 경우고, 시간대도 두 가지로 나누어 분리 합산 후 비교하거나, 일별, 주별, 월별, 특정 기간별 선택을 해서 집계할 수 있어야 했으므로 사실 데이터버퍼들은 아래에 표현된것보다 조금 더 많고 구조도 복잡하다.
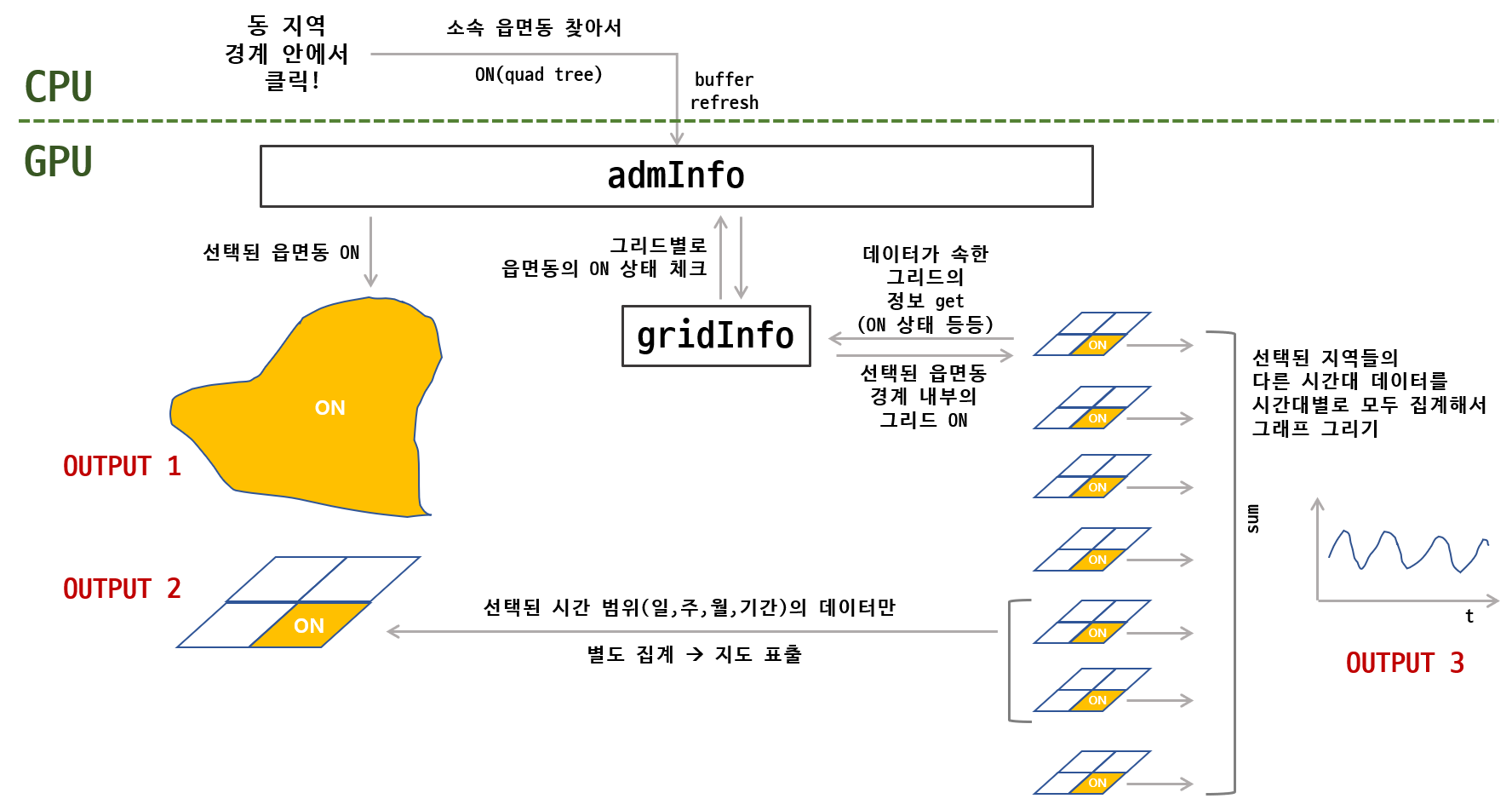
위 그림의 흐름은 이렇다.
동 지역 경계안에서 클릭하면 quad tree 로 미리 입력된 데이터 안에서 어떤 경계인지 빠르게 찾아낸다. 읍면동만 찾아낸 후, 시군구와 시도는 위에서 설정한 배열을 이용하여 지시적으로 접근&조회할 수 있다. (최근에 깨달았는데 이 경우에는 Rtree가 좀 더 적합하다. quad tree에서는 골뱅이처럼 빙글빙글 반경을 넓혀가며 주변을 검색해 나가는 방식을 구현해서 사용했는데 Rtree는 걸쳐지는 bounding box들을 한번에 찾아낼 수 있기 때문이다.)
어떤 읍면동인지 찾아냈으면, admInfo라는 이름의 변수에 마킹을 한다. 하나 위에서 보여준 읍면동 배열에서 해당 읍면동에 접근해서 0을 1로 바꿔주면 된다.
여기까지가 cpu에서 이루어지는 작업이다. 업데이트 된 소량의 버퍼를 다시 gpu에 밀어넣고 나면 그 다음에는 모두 gpu에서 연산되어 화면에 출력된다.
raw data전체는 날짜나 선택영역 등 옵션의 변화가 있을 때마다 compute shader에서 재집계 작업을 하게 된다. compute shader 안에서는 전체 raw data를 순회하면서, 앞서 설명했던 gridInfo에서 소속 읍면동을 조회하고, 다시 admInfo에 접근해서 해당 읍면동이 선택되었는지 조회한다. 그래서 선택된 그리드라면 그래프용으로 집계를 하고, 추가적으로 화면에 표출되는 날짜인지 체크해서 지도 표출용을 집계한다.
그렇게 정리된 데이터는 vertex shader와 geometry shader를 거치면서 화면에 출력되는 동시에 약간의 후 작업을 하게 된다.
데이터의 속성에 따라 위의 처리 과정을 모두 다 compute shader에서 수행하거나, 일부는 그리면서 geometry shader에서 수행하기도 했다. 개념상으로는 compute shader에서 모두 처리하는게 깔끔하고 명료하지만, 퍼포먼스를 고려하다보니 기왕 데이터에 한 번 접근할 때 해당 데이터를 업데이트 하는 방식을 택하게 되었다.
그렇게 처리한 데이터는 위에서 여러차례 보여준 것처럼 지도와 시계열 그래프에 표현된다.

위 처럼 선택된 그리드들을 bit 단위로 관리하는 버퍼를 두어 연산에 보조적으로 이용했다. 위의 흐름도 중간중간에 이 selectedGrid변수를 거친다고 보면 된다. 처음에는 gridInfo 변수의 남는 비트를 사용하였으나, gridInfo는 const 성질의 변수에 해당하고 이 변수는 수시로 바뀌거나 초기화 한 전체 버퍼를 덮어 씌울 필요가 있어 별도로 관리하게 되었다.
선택에 따라 수시로 업데이트 되는 selectedGrid 변수를 이용하여 아래처럼 표현할 수 있다.

끝.
'Function' 카테고리의 다른 글
| 벡터필드 : 풍속 데이터로 바람 그리기 (0) | 2022.01.24 |
|---|---|
| 겹치지 않는 원으로 인구 그려보기 (0) | 2021.12.29 |
| 지구를 그려보자 (0) | 2021.10.29 |
| 스마트서울 도시데이터센서(S-DoT)기온 데이터 시각화 (6) | 2021.10.11 |
| OD 시각화 3 : 서울 생활이동 데이터를 지도 위에 옮겨보자 (4) | 2021.09.10 |



