
웹에서 대용량 공간 데이터를 시각화하는건 2024년이라는 시점에서 이미 새로운 기술은 아니다. 구글 맵이나 카카오 네이버 맵에서는 오래 전부터 전세계나 우리나라 전체의 지도를 브라우징하면서 필요한 장소들을 찾을 수 있도록 서비스 해 왔다. 브이월드 같은 3차원 지도 역시 서비스된 지 10년이 넘었다.
그런데 그런 대규모 기업형 서비스가 아니라 다소 소박한 환경에서 웹 컨텐츠를 만든다고 해보자. 로컬에서 파일을 올려 웹브라우저에서 시각화하는 경우라면 그리 문제는 안 된다. 보통의 컴퓨터들의 성능이 많이 좋아졌기 때문에 웬만한 컴퓨터에서 웹브라우저로 100MB 남짓의 데이터를 올려서 그리는건 큰 문제가 되지 않는다.
kepler.gl 같은 deck.gl 기반의 서비스가 바로 그러한 경우다. 사이트에 접속한 후 로컬에서 100MB 정도 파일을 웹브라우저에 드래그&드롭하면 금세 지도 위에 시각화된 멋진 결과물을 볼 수 있다. 파일이 다른 곳으로 전송되지 않기 때문에 인터넷 송수신 환경을 크게 신경쓰지 않아도 된다.
그런데 조금 큰 파일을 웹 사이트에 접속해서 보게 될 경우에는 어떻게 해야 할까? 어느 정도 크기의 파일까지 '큰 문제'가 없을까? 10MB 정도는 괜찮겠지. 20MB정도도.. 괜찮겠지. 50MB는? 전송되는데 약간의 시간이 걸리겠지만 pc환경이라면 그리 큰 부담은 없다. 그런데 100MB라면? 좀 무리스럽다는 생각이 들지 않은가?
그나마 이건 서비스를 이용하는 사람의 입장이다. 서비스를 제공하는 입장이라면 좀 더 신경이 쓰인다. 50MB를 100명이 접속해서 받아가면 5GB의 트래픽이 발생한다. 하물며 접속자 1인당 100MB를 받아간다면? 컨텐츠가 잘 팔려서 접속자가 갑자기 늘어난다면? 접속자 수 만큼 수익이 따르는게 아닌 경우, 종량제 클라우드 서비스라도 이용하는 입장에서는 아마도 꽤 신경이 쓰일 것 같다.
대부분의 경우 데이터가 10MB 정도만 되어도 잘 풀어놓으면 화면 안에 가득 찬다. 그게 그래프든 지도 위에 그리든 비슷하다. 그 말인 즉슨, 접속했다가 곧 떠날 사람들에게 한 번 접속으로 100MB를 건네주는건, 만약 그게 송수신 측에서 큰 부담이 없는 일이라고 할 지라도 인터넷 트래픽만 불필요하게 발생시키는 일이 되어버린다는 의미다. 지도 위의 공간 데이터라고 한다면 접속한 공간 영역만큼, 브라우징한 줌 레벨에 맞는 만큼만 데이터를 제공해주는게 여러 모로 건강하다.
지도 서비스에서 보편화된 타일맵이 바로 이런 요구들과 맞아떨어지는 해결책이다. 접속한 줌 레벨과 공간 범위만큼만 미리 준비된 타일들을 제공한다. 과거에는 래스터 타일이 많이 사용되었지만, 최근에는 벡터 타일을 점점 많이 쓰는 추세다. 화면의 복잡도에 따라 용량도 작아질 수 있고, 무엇보다 클라이언트에서 재가공해서 보여주기에 좋다는 장점이 있다.
그래서 중간의 질문으로 다시 돌아가보자. 좋은건 알겠는데 '소박한 환경'에서 어떻게 구현하느냐는거다. 전국에 퍼져 있는 100MB정도의 포인트 데이터가 있고, 만약 맡은 일이 그 데이터를 지도 위에 띄워야 하는 것이라면? 짧은 시간에 최대한 효율적으로 컨텐츠를 만들어야 한다면?
비용을 조금 들인다면 맵박스 같은 서비스를 이용하는게 가장 편하다. 데이터를 업로드하면 알아서 타일맵을 만들어준다. 데이터는 해결되었으니 시각화만 구현하면 된다. 그런데 돈도 없다면? github page를 이용해서 만들면 된다. 100MB의 데이터를 잘개 쪼갠 벡터 타일맵은 직접 만들면 된다. 이 글에서 설명할 내용이 바로 벡터 타일을 만드는 절차다.
벡터 타일 맵을 만드는 과정이 그리 대단한 건 아니다. 라이브러리도 많이 있는 것 같고, 라이브러리 하나를 골라 살만 좀 붙여나가면 된다. 물론 처음 접근하는 사람에게는 넘기에 힘든 산처럼 보일 수도 있다. 이 글은 그 산을 동네 언덕처럼 좀 더 쉽게 넘도록 도와주는 가이드다.
이런. 서론이 너무 길었다.
벡터 타일을 이용해서 만든 결과물이 궁금하면 아래 사이트를 먼저 들어가보자. 전국의 건물 700만동이 모두 들어가 있다.
모바일에서도 잘 된다. 다만, 여기저기 돌아다니다 보면 몇십MB 이상을 받게 될 수 있으니 데이터 무제한이 아니라면 전송량을 신경써야 한다.
All buildings Korea
vuski.github.io
벡터 타일 만드는 절차
벡터 타일은 Qgis의 공간처리 툴 박스에도 만드는 함수가 존재한다. 클릭 몇 번으로 편하고 빠르게 타일맵을 만들어준다. 단, 작은 줌 레벨에서 폴리곤 단순화 처리를 하는데 그게 좀 매끄럽지 못하다. 폴리곤을 단순화시키면서 상태를 엉망으로 만들어버린다. 그래서 여기서는 파이썬에서 여러 절차를 직접 수행하며 커스터마이징 해본다..
벡터 타일은 다음의 순서로 만든다.
1. 줌 레벨에 따라 제공할 파일들을 만든다.
포인트 데이터라면 줌 레벨이 낮을 때는 주요한 일부 데이터만 필터링하거나, 몇몇 데이터를 뭉쳐서 하나의 포인터로 보여줄 수도 있다. 줌 레벨에 따른 구현은 순전히 컨텐츠 제공자의 판단에 따르는 영역이다.
건물 폴리곤 데이터라면 줌 레벨이 낮을 때는 주요한 건물이나 규모가 큰 건물만 남길 수도 있다. 작은 건물들이 있는 블록은 하나의 폴리곤으로 그릴 수도 있다.
시군구, 읍면동 경계라면 줌 레벨이 낮을 때는 아예 보여주지 않는 방법도 있다. 폴리곤을 단순화 시켜서 용량을 줄일 수도 있겠다.
2. 줌 레벨별로 타일링 작업을 한다.
타일 영역을 계산해서 사각형을 만든다. 라인이나 폴리곤이라면 사각형과 교차하는 부분만 잘라낸다. 포인트 데이터라면 사각형에 포함되는 데이터들을 필터링하면 된다.
3. 정해진 폴더 구조에 맞게 저장한다.
[zoom번호] / [x tile번호] / [y tile 번호].mvt 의 폴더와 파일 구조가 된다.
4. (선택)필요에 따라 타일들을 병합한다.
큰 데이터로 작업할 경우 각각의 데이터를 폴더 구조에 맞게 저장해 둔 뒤, 이를 병합(merge)하는 작업을 한다.
물론 한 번에 작업해도 되지만 메모리가 부족할 수도 있고, 데이터가 방대해지면 처리 속도가 떨어질 수도 있다. 파일 시스템을 이용한 사전 분할 및 병합은 HDD 시절에는 작은 파일 처리 시간 지연으로 인해 부담스러웠지만 SSD에서는 그리 부담스런 작업은 아니다.
벡터 타일과 라이브러리 개요
대부분의 xyz 타일은 Mercator 좌표계(EPSG:3857) 기반의 좌표계를 사용하며, Zoom 레벨에 따라 다른 스케일로 X 번호와 Y 번호가 매겨진 타일들로 구성된다. 따라서 x,y,z(zoom) 값만 알면 공간의 영역을 결정할 수 있다. 이런 표준 사양이 있으므로 래스터나 벡터 타일 모두 같은 타일 번호라면 같은 공간 안에 매칭시킬 수 있다.
여기서 설명할 벡터 타일도 xyz 타일 기반의 MVT(Mapbox Vector Tile)이다. 맵박스에서 만든 스펙이지만 여기저기 많이 쓰인다. OSM 데이터의 파일 형식으로 주로 사용되는 PBF와 1:1로 호환된다.(확장자만 바꾸면 사실상 같다고 하는데 확인은 못 해 봤다.) 그리고 강력한 공간 시각화 라이브러리인 Deck.gl에서 바로 불러올 수 있다는 장점도 있다.
Python을 이용해서 변환 작업을 했다.
mvt 파일은 아래의 라이브러리를 이용해서 만들었다.
지금은 문을 닫은 Mapzen에서 관리하던 계정인 듯 하다.
GitHub - tilezen/mapbox-vector-tile: Python package for encoding & decoding Mapbox Vector Tiles
Python package for encoding & decoding Mapbox Vector Tiles - tilezen/mapbox-vector-tile
github.com
그런데 이 라이브러리는 그저 좌표값들을 mvt 형식으로만 바꾼다. 타일 영역이든 그렇지 않든 전혀 개의치 않는다. 따라서 타일 영역으로 데이터를 자르고 폴더 트리에 넣는 작업은 직접 구현해야 한다.
다행히도 타일 번호에 따른 공간 영역은 mercantile 라이브러리를 통해 구할 수 있다.
맵박스에서 제공하는 파이썬 라이브러리다.
GitHub - mapbox/mercantile: Spherical mercator tile and coordinate utilities
Spherical mercator tile and coordinate utilities. Contribute to mapbox/mercantile development by creating an account on GitHub.
github.com
파이썬에서는 shapely 라이브러리로 타일과 교차영역 계산 등 주요한 작업들을 한다.
폴리곤 파일 전처리에 필요한 단순화 작업은 mapshaper 라이브러리를 이용한다.
폴리곤 단순화에는 mapshaper 만한 라이브러리가 없다. 경계가 서로 맞닿은 행정구역 경계 같은 경우에도 토폴로지만 깔끔하게 맞아떨어지는 파일이면 복잡한 부분을 단순화하면서 경계 맞물림도 보전해준다.
R이라면 포팅된 라이브러리가 있지만 파이썬은 없다. 그래서 노드 버젼 맵셰이퍼를 설치한 후 커맨드 모드로 실행시켜서 파이썬 프로세스에 병합시킨다.
줌 레벨과 타일맵의 크기는 아래 사이트에서 볼 수 있다.
Tiles à la Google Maps: Coordinates, Tile Bounds and Projection | No code | MapTiler
How does a zoomable map work? Coordinate systems and map projections, transform the shape of Earth into usable flat online maps.
docs.maptiler.com
서울 지역을 옮겨봤다. Google(54,24) 처럼 나오는 부분이 타일 맵 번호다.
줌 레벨 14정도면 웬만한 벡터 타일은 몇십~몇백KB 수준으로 담을 수 있다.

세부 코드들 중 일부는 chatGPT를 활용해서 얻은 후 수정을 거쳐 만들었다.
chatGPT가 없던 시절이라면, 검색하는데 훨씬 더 많은 시간이 걸렸을 것 같다.
그럼 이제 순서대로 다시 가 보자.
이 글에서는 폴리곤, 라인, 포인트의 순서로 설명한다.
폴리곤의 경우 줌 레벨에 맞는 파일 전처리 작업이 필수다.
라이브러리 준비
pyshp, shapefile, mapbox_vector_tile, mercantile, pyproj, pandas 등이 필요하다.
import os
import shapefile
import mapbox_vector_tile
from mapbox_vector_tile.encoder import on_invalid_geometry_make_valid
import mercantile
from shapely.ops import transform
from shapely import affinity
from shapely.geometry import shape, mapping, Polygon, MultiPolygon, LinearRing, LineString, MultiLineString
from shapely.geometry.polygon import orient
import pyproj
from collections import defaultdict
import pandas as pd
import subprocess
node 라이브러리는 mapshaper는 터미널에서 실행시킬 예정이므로 터미널에서 아래처럼 설치한다.
npm install -g mapshaper
폴리곤 파일 전처리
일단 행정구역 경계를 기준으로 설명하겠다.
아래의 읍면동 경계를 바탕으로 작업한다.
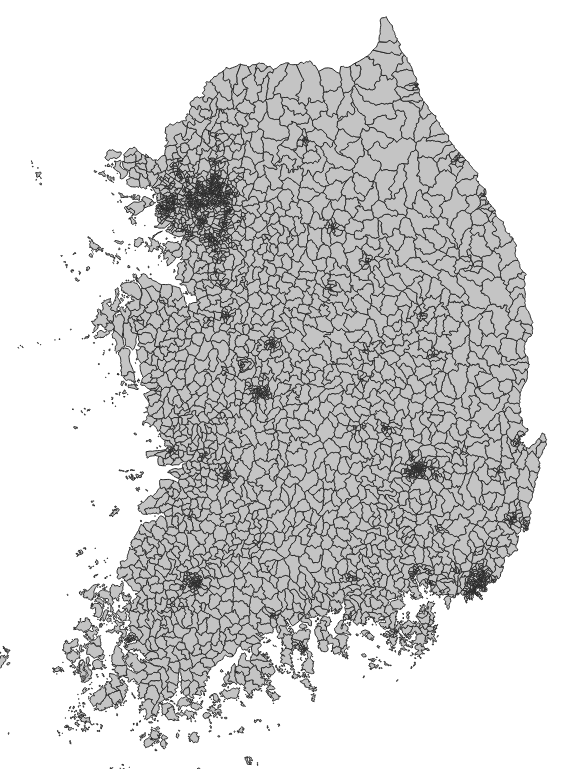
이 읍면동 경계는 토폴로지 오류가 거의 대부분 수정되어 있다. 속성에 담긴 시군구나 시도 코드로 dissolve 하면 깔끔하게 상위 경계를 만들 수 있다.
아래의 과정으로 처리한다.
1. 줌 레벨 1부터 14까지 루프를 돌면서 작업한다.
2. 각각의 줌 레벨에서 해당 레벨에 맞게 읍면동 경계를 mapshaper로 단순화 처리를 한다.
3. 단순화 된 읍면동 경계를 바탕으로 dissolve해서 시군구 경계를 만든다.
4. 시군구 경계를 바탕으로 dissolve해서 시도 경계를 만든다.
5. 각각의 결과는 중간 작업 폴더에 저장한다. 줌 레벨이 3이라면 emd_3.shp로 저장한다.
파이썬 코드는 다음과 같다.
### 미리 emd 파일을 베이스로 해서 줌 레벨에 따라 단순화 및 dissolve를 수행하는 코드
### sgg와 sido 단위 역시 emd로부터 만들어냄
### 경계가 잘 맞아야 하기 때문
input_file = "z:/temp/새 폴더/emd.shp"
output_folder = "z:/temp/새 폴더/simplified/"
os.makedirs(output_folder, exist_ok=True)
for zoom_level in range(1, 15):
simplified_file = os.path.join(output_folder, f"emd_{zoom_level}.shp")
simplification_ratio = pow(zoom_level/14,2) # 예시로 줌 레벨에 따른 단순화 비율 설정
simplify_with_mapshaper(input_file, simplified_file, simplification_ratio)
# Dissolve by sido, sidonm, sgg, sggnm
dissolved_file_sgg = os.path.join(output_folder, f"sgg_{zoom_level}.shp")
dissolve_with_mapshaper(simplified_file, dissolved_file_sgg, ['sidocd', 'sidonm', 'sggcd', 'sggnm'])
# Dissolve by sido, sidonm
dissolved_file_sido = os.path.join(output_folder, f"sido_{zoom_level}.shp")
dissolve_with_mapshaper(dissolved_file_sgg, dissolved_file_sido, ['sidocd', 'sidonm'])
print("Shapefiles simplified and dissolved successfully.")
mapshaper의 단순화 계수는 다음과 같이 간단히 정했다.
실제로는 https://mapshaper.org/ 에 접속해서 읍면동 경계를 넣어놓고 단순화 결과를 직접 눈으로 보면서 계수를 배열 등으로 수동 지정하는 방법을 권장한다.
simplification_ratio = pow(zoom_level/14,2)
위에서 사용한 함수들은 아래와 같다.
def run_mapshaper_command(command):
print(f"Running command: {' '.join(command)}")
subprocess.run(command, check=True)
def simplify_with_mapshaper(input_file, output_file, simplification_ratio, write_fields=[], \
read_encoding='utf8', write_encoding='utf8'):
mapshaper_path = os.path.join('./', 'node_modules', 'mapshaper', 'bin', 'mapshaper')
output_file_normalized = output_file.replace('\\', '/')
# mapshaper 명령어를 사용하여 데이터 단순화
# mapshaper 명령어 경로 지정
# npm install mapshaper 필요함
command = [
'node', mapshaper_path, input_file,
#'-encoding', read_encoding, # 읽기 시 인코딩 옵션
'-simplify', str(simplification_ratio),
'-clean'
]
# write_fields가 비어 있지 않으면 해당 필드만 남기도록 필터 추가
if write_fields:
fields = ','.join(write_fields)
command.extend(['-filter-fields', fields])
print("write_name : ", output_file_normalized)
# 출력 파일 지정
command.extend(['-o', output_file_normalized, f'encoding={write_encoding}'])
run_mapshaper_command(command)
def dissolve_with_mapshaper(input_file, output_file, dissolve_fields):
mapshaper_path = os.path.join('./', 'node_modules', 'mapshaper', 'bin', 'mapshaper')
dissolve_command = [
'node', mapshaper_path, input_file,
'-dissolve', ','.join(dissolve_fields),
'-clean',
'-o', output_file
]
run_mapshaper_command(dissolve_command)
앞에서도 언급했지만 mapshaper는 Node.js 라이브러리이므로 Node가 설치되어 있지 않다면 당연히 터미널에서 Node 먼저 설치해야 한다.
파이썬에서 subprocess.run(command) 함수로 cmd 명령어를 실행할 수 있다.
여기까지 제대로 진행되었다면 위에서 output으로 설정한 simplified 폴더에 다음과 같은 파일들이 생성된다.
이 파일들은 다음 단계에서 소스로 활용된다.

이제 줌 레벨별 재료가 만들어졌으므로 타일 맵을 만들어보자.
전처리한 파일로 타일 맵 만들기
타일 맵은 아래와 같은 순서로 만든다.
tiles_data = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
source_folder = "z:/temp/새 폴더/simplified"
__MVT_EXTENT = 4096
#폴리곤을 포함하면 당연히 주변의 둘레 라인도 그릴 수 있지만
#picking 과 같은 이유 등으로 폴리곤을 제외하고 라인만 그릴 경우에는
#아래 옵션을 조정하면 된다.
isIncludingLines = True
isIncludingPolygon = True
zoom_levels = range(10,15)
process_polygon_layer("emd", source_folder, zoom_levels, tiles_data, __MVT_EXTENT, isIncludingPolygon, isIncludingLines)
zoom_levels = range(7,15)
process_polygon_layer("sgg", source_folder, zoom_levels, tiles_data, __MVT_EXTENT, isIncludingPolygon, isIncludingLines)
zoom_levels = range(1,15)
process_polygon_layer("sido", source_folder, zoom_levels, tiles_data, __MVT_EXTENT, isIncludingPolygon, isIncludingLines)
읍면동은 줌 레벨 10부터 14까지만 만든다. deck.gl에서 mvtLayer로 시각화 할 때 min과 max 레벨을 설정할 수 있다. 읍면동 같은 경우 min을 10으로 설정하면 10레벨 이하에서는 불러들이지 않고 객체도 보이지 않는다. max를 14로 설정하면 14이상에서는 14에서 불러들인 타일을 계속 보여주게 된다.
시군구는 7레벨부터 14레벨까지 만든다. 최상위 레벨은 맞춰줘야 된다. 14레벨의 단순화 처리된 읍면동은 그보다 낮은 레벨에서 단순화 처리된 시군구 경계와는 약간 어긋나기 때문이다.
같은 원리로 시도경계는 1레벨부터 14레벨까지 만든다.
사실 1,2레벨정도라면 시도 경계 보다는 전 국토 경계가 어울리지만, 그냥 여기서는 거기까지는 구현하지 않았다. 사실 코드 두 줄만 추가하면 되는데, 그건 각자의 몫으로 두겠다.
MVT_EXTENT로 설정한 4096은, 맨 마지막 단계에서 파일을 mvt로 인코딩 할 때 넣어야 하는 필수 변수다.
타일 안의 객체들을 4096개로 쪼개서 정수화된 좌표로 넣는다. 줌 레벨 14같은 경우는 가로세로 2.2km 정도인데, 그렇다면 2200/4096 = 0.59m 보다 인접한 자세한 좌표는 같은 좌표로 추가할 수 없다는 의미다. 건물 같은 경우는 그 보다 자세한 좌표가 필요할 수도 있으므로 8192등으로 올려서 저장하면 된다.
단, 하나의 mvt 파일에 건물, 시도 경계, 도로 등 레이어를 구분해서 모두 넣을 수 있는데, 같은 mvt 파일에서는 MVT_EXTENT 값이 모두 같아야 한다는 점을 미리 염두에 두자. (되는지 안되는지 끝까지 확인은 못했지만 mapbox_vector_tile 라이브러리에서는 하나의 extent 값으로 인코딩 변환하게 된다.)
isIncludingLines와 isIncludingPolygon 은 아웃풋 형식에 관련에 관련된 매개변수다.
폴리곤을 집어 넣었을 때 lineString형식의 데이터로 변환해서 뽑아내야 할 경우가 있다. 물론 폴리곤 벡터 타일 맵을 그릴 때 면은 칠하지 않고 테두리만 표현되도록 할 수도 있다. 그런데 특수한 경우도 있다. 읍면동 시군구 시도 경계를 한 mvt에 넣어 놓고 테두리를 한 번에 겹쳐 그린 뒤 읍면동 면을 기준으로 onClick이나 onHover 를 작동시켜야 할 경우도 있다.
이 때는 mvt 레이어를 emd_line, sgg(폴리곤), sido(폴리곤), emd(폴리곤) 순서로 읽은 뒤 그리도록 설정해야 한다. 그래야 시군구 경계선이 읍면동 경계선을 덮어 그리고, 시도 경계선이 시군구 경계선을 덮어서 그린다. 물론 면은 칠하지 않고 테두리만 그리는 경우다.


그런데 시도 경계가 가장 위에 있게 되면 경계 면은 깔끔하게 그려지지만, 가장 밑에 깔린 읍면동 면에 마우스 이벤트를 지정하기 까다롭다. (적어도 deck.gl의 mvtLayer에서는 그렇다) 그래서 다시 가장 위에 읍면동 면을 덮어 그려서 마우스 이벤트가 감지되도록 한다.
여튼 이러한 이유 등으로 line을 별도로 만들어야 할 필요가 있어서 함수 안에 내용을 집어넣었다. polygon이나 line이나 타일의 용량 차이는 거의 없으므로, 대부분의 경우에는 polygon만 만들면 된다.
다시 위의 코드로 돌아가보자. 보면 알겠지만, 핵심은 process_polygon_layer다.
이 함수가 실행되면 매개변수로 넘겨준 tiles_data 에 처리된 데이터가 누적된다. 굳이 리턴하지 않아도 리셋하기 전까진는 계속 누적되고 있다고 보면 된다.
일단 함수 전체 코드를 보자.
def process_polygon_layer(layer_name, folder_name, zoom_levels, tiles_data,\
_MVT_EXTENT = 4096, isIncludingPolygon=True, isIncludingLines=False,\
source_crs_manual = "EPSG:3857"):
# zoom_levels를 하나씩 순회
for zoom_level in zoom_levels:
# 사용 예제
filename = f"{folder_name}/{layer_name}_{zoom_level}.shp"
shape_records = read_and_transform_shapefile(filename, source_crs_manual)
print(f"Processing zoom level {zoom_level}, {filename}...")
buf = calculate_tile_cut_buffer(zoom_level, _MVT_EXTENT)
# simplified_shapes를 하나씩 순회
for geom, record in shape_records :
bounds = geom.bounds
#print(bounds)
min_tile = mercantile.tile(*projectTo4326(bounds[0], bounds[3]), zoom_level)
max_tile = mercantile.tile(*projectTo4326(bounds[2], bounds[1]), zoom_level)
#print(min_tile)
#print(max_tile)
# min_tile부터 max_tile까지 순회
for x_tile in range(min_tile.x, max_tile.x + 1):
for y_tile in range(min_tile.y, max_tile.y + 1):
bounds = mercantile.xy_bounds(x_tile, y_tile, zoom_level)
tile_box = Polygon([
(bounds.left-buf, bounds.bottom-buf),
(bounds.left-buf, bounds.top+buf),
(bounds.right+buf, bounds.top+buf),
(bounds.right+buf, bounds.bottom-buf),
(bounds.left-buf, bounds.bottom-buf)
])
# geom과 tile_box의 교집합 계산
intersection = tile_box.intersection(geom)
if intersection.is_empty:
continue
transformed_polygon = affinity.translate(intersection, xoff=-bounds.left, yoff=-bounds.bottom)
transformed_polygon = affinity.scale(transformed_polygon,
xfact=_MVT_EXTENT/(bounds.right-bounds.left), yfact=_MVT_EXTENT/(bounds.top-bounds.bottom),
origin=(0, 0, 0))
if (isIncludingPolygon) :
serialized_geom = {
"geometry": transformed_polygon,
"properties": record,
}
# tiles_data에 저장
tiles_data[zoom_level][(x_tile, y_tile)][layer_name].append(serialized_geom)
if (isIncludingLines) :
if isinstance(intersection, Polygon):
exterior_coords = transformed_polygon.exterior.coords
interior_coords = [interior.coords for interior in transformed_polygon.interiors]
exterior_line = LineString(exterior_coords)
if interior_coords:
interior_lines = [LineString(coords) for coords in interior_coords]
transformed_linestring = MultiLineString([exterior_line] + interior_lines)
else:
transformed_linestring = exterior_line
elif isinstance(intersection, MultiPolygon):
exterior_lines = [LineString(p.exterior.coords) for p in transformed_polygon.geoms]
interior_lines = [LineString(interior.coords) for p in transformed_polygon.geoms for interior in p.interiors]
if interior_lines:
transformed_linestring = MultiLineString(exterior_lines + interior_lines)
else:
transformed_linestring = MultiLineString(exterior_lines)
serialized_linestring = {
"geometry": transformed_linestring,
"properties": record,
}
tiles_data[zoom_level][(x_tile, y_tile)][f'{layer_name}_line'].append(serialized_linestring)
#return tiles_data
가장 상위에서 줌 레벨 한 단계씩 작업한다.
read_and_transform_shapefile 에서는 shp 파일을 읽고, 좌표계가 다른 경우 타일 좌표계인 EPSG 3857로 변환해준다.
for zoom_level in zoom_levels:
# 사용 예제
filename = f"{folder_name}/{layer_name}_{zoom_level}.shp"
shape_records = read_and_transform_shapefile(filename, source_crs_manual)
print(f"Processing zoom level {zoom_level}, {filename}...")
파일을 읽었으면, 이제 shape 파일의 도형 하나하나씩 작업한다.
파일 전체로 해도 될 것 같지만, intersection 등에서 정상적인 폴리곤을 산출하지 못하거나 오히려 오래 걸리는 경우도 있었다.
for geom, record in shape_records :
bounds = geom.bounds
#print(bounds)
min_tile = mercantile.tile(*projectTo4326(bounds[0], bounds[3]), zoom_level)
max_tile = mercantile.tile(*projectTo4326(bounds[2], bounds[1]), zoom_level)
#print(min_tile)
#print(max_tile)
# min_tile부터 max_tile까지 순회
for x_tile in range(min_tile.x, max_tile.x + 1):
for y_tile in range(min_tile.y, max_tile.y + 1):
bounds = mercantile.xy_bounds(x_tile, y_tile, zoom_level)
tile_box = Polygon([
(bounds.left-buf, bounds.bottom-buf),
(bounds.left-buf, bounds.top+buf),
(bounds.right+buf, bounds.top+buf),
(bounds.right+buf, bounds.bottom-buf),
(bounds.left-buf, bounds.bottom-buf)
])
# geom과 tile_box의 교집합 계산
intersection = tile_box.intersection(geom)
먼저 도형 하나의 bounding box 경계를 구한다. 그 후에 타일 범위를 mercantile 라이브러리를 이용해서 구한다. mercantile은 위경도 좌표계를 받으므로 입력 좌표계를 그에 맞게 변환해준다.
타일 번호를 받았으면 타일을 순회하면서 폴리곤과의 intersection을 구한다.
타일 경계에 해당하는 사각형 박스는 mercantile.xy_bounds 를 통해서 구할 수 있다.
교차 작업에 사용할 최종 경계는 여기에 약간의 버퍼를 주어 주변으로 offse한다. 이건 폴리곤에서만 필요한 작업인데 deck.gl에서 그릴 때 타일 경계선이 드러나지 않도록 하기 위함이다.
타일로 잘린 폴리곤은 당연히 아래처럼 타일 경계선을 따라 테두리가 만들어지고, 그래서 그대로 면을 칠하고 경계선을 stroke하면 그다지 보기에 좋지 않다.

그런데 타일 크기보다 약간 더 크게 잘라서 타일을 만들면, 나중에 deck.gl에서 그릴 때 타일 바깥 부분은 clipping을 하면서 자동적으로 잘린다. 즉, 타일 경계선은 타일 바깥쪽에 있으므로 자연스럽게 경계선이 표현되지 않는다. 클리핑 작업은 webgl 프로세스 중의 하나로서 비용이 별로 발생하지 않는다. fragment shader 이후에 픽셀 단위에서 이루어지는 gpu 작업이기 때문이다.

타일로 잘린 폴리곤들은 타일의 좌측 하단점을 ( 0, 0 )으로 하는 상대 좌표로 변환시켜야 한다. 동시에 우측 상단 점도 (MVT_EXTENT, MVT_EXTENT) 로 맞춰준다.
아래는 shapely.affinity 함수를 이용해서 폴리곤 전체의 좌표를 변환하는 작업이다. 타일을 벗어나는 좌표는 음수가 되거나 MVT_EXTENT보다 크겠지만, 상관은 없다.
transformed_polygon = affinity.translate(intersection, xoff=-bounds.left, yoff=-bounds.bottom)
transformed_polygon = affinity.scale(transformed_polygon,
xfact=_MVT_EXTENT/(bounds.right-bounds.left), yfact=_MVT_EXTENT/(bounds.top-bounds.bottom),
origin=(0, 0, 0))
마지막으로 mapbox_vector_tile 라이브러리에서 요구하는 형식에 맞춰 준다. 최종적으로는 tiles_data 딕셔너리에 입력하는데 [줌레벨] [x,y타일번호] [레이어 이름] 을 key값으로 둔다. 나중에 다시 순회하면서 인코딩한 뒤 폴더와 파일들로 저장해야 하기 때문이다.
serialized_geom = {
"geometry": transformed_polygon,
"properties": record,
}
# tiles_data에 저장
tiles_data[zoom_level][(x_tile, y_tile)][layer_name].append(serialized_geom)
if (isIncludingLines) 이하 부분은 라인으로 변환한 뒤 레이어 이름이 '_line'을 덧붙여서 저장하는 내용이다. polygon과 multipolygon을 구분해야 하고, polygon에서 바깥쪽 테두리와 hole에 해당하는 부분들을 구분해야 해서 코드가 다소 길어졌다.
read_and_transform_shapefile와 calculate_tile_cut_buffer 등의 하위 함수들은 나중에 첨부할 전체 코드에 담았다.
타일들을 폴더 구조에 맞춰 인코딩 후 저장하기
이제 마지막 단계다.
줌 레벨별로 순회, 그 안에서 x,y타일번호로 순회한다.
import os
import mapbox_vector_tile
# 타일 저장 디렉토리 설정
tile_dir = "Z:/temp/public/building/"
__MVT_EXTENT = 4096
# 누적된 데이터를 MVT 파일로 저장
for zoom_level, tiles in tiles_data.items():
for (x_tile, y_tile), features in tiles.items():
tile_path = os.path.join(tile_dir, str(zoom_level), str(x_tile))
os.makedirs(tile_path, exist_ok=True)
mvt_path = os.path.join(tile_path, f"{y_tile}.mvt")
all_features = []
for layer_name, layer_features in features.items():
tile_layer = {
"name": layer_name,
"features": [{
#geometry와 properties이외의 필드를 넣으면
#mvt의 fields에 추가된다.
#"id" : get_layer_value(layer_name),
"geometry": feat["geometry"],
"properties": feat["properties"] } for feat in layer_features]
}
all_features.append(tile_layer)
with open(mvt_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, \
default_options={"extents":__MVT_EXTENT,
"y_coord_down" : False,
"check_winding_order" : True,
"on_invalid_geometry": on_invalid_geometry_make_valid},
))
앞서 각 타일마다 emd, emd_line, sgg, sgg_line, sido, sido_line의 여섯개 레이어가 만들어졌다. 이 레이어를 순회하면서 정해진 형식대로 객체를 만든다.
최종적으로는 mvt 파일로인코딩 하면서 곧바로 저장한다.
인코딩 함수에는 몇 개의 유효한 매개변수들이 있다. "extents" 는 앞서 설정해 준 값을 넣는다. 그러면 인코딩하면서 0~MVT_EXTENT 사이의 값으로 인코딩 되었던 좌표들이 다시 0~1 사이의 값으로 변환된다. 타일 바깥으로 offset된 부들은 0보다 작거나 1보다 커지지만 상관 없다.
check_winding_order이 True로 활성화 된 상태에서, y_coord_down을 False로 해주면 모든 폴리곤의 방향을 시계방향으로 정정해준다. 바깥쪽 링 CW, 안쪽 링 CCW가 mvt 파일의 표준 스펙이다. 내부 코드를 보면 shapely 라이브러리로 구현하고 있다. y_coord_down을 True로 하면 바깥쪽 링을 CCW, 안쪽 링을 CW로 정렬해준다. 디폴트 값이 위에서 설정한 값이므로 일반적인 경우라면 사실 두 옵션은 써 주지 않아도 괜찮다.
여기까지 되었다면 곧바로 사용할 수 있는 mvt들이 만들어졌다.
QGIS에 특정 줌 레벨 폴더 전체를 드래그&드롭하면 결과물을 확인할 수 있다.
고맙게도 QGIS에서는 mvt파일들을 자동적으로 인식해서 폴더 이름과 파일 이름에 맞춰 위치들을 좌표공간에 맞게 지정해준다. 실험삼아 mvt 파일 하나를 다른 폴더로 옮긴 후 드래그&드롭해보면 엉뚱한 위치에 그려지고 좌표계도 물음표로 나온다. QGIS는 해당 파일의 폴더 구조 번호를 토대로 로딩하기 때문이다. 파일 하나에는 extent와 0~1사이의 상대 좌표만 있으므로 엉뚱한 폴더의 파일 하나를 대하는 프로그램 입장에서는 이 객체들이 어디에 위치했는지 인식할 수 없다.
예시 : 건물 폴리곤 변환
이번에는 건물 폴리곤을 변환해보자.
먼저 도로명주소지도에서 전자지도를 신청해서 다운받는다. 신청 후 하루 정도면 다운받을 수 있는 링크를 준다.
압축을 풀어서 다음과 같은 시도별 폴더 구조로 만든다. 각 폴더 아래에는 TL_SPBD_BULD.shp 파일이 있다.

이제 이 폴더 이름들을 읽는다.
source_folder = "X:/#도로명주소 지도_국가공간정보유통시스템/202312_전국/전자지도/"
# source_folder의 1차 하위 폴더 읽기
# 1차 하위 폴더의 이름만 변수에 저장. 상위 경로는 제외
sub_folders = [f.name for f in os.scandir(source_folder) if f.is_dir()]
sub_folders
# 결과가 아래처럼
['11000',
'26000',
'27000',
'28000',
'29000',
'30000',
'31000',
'36000',
'41000',
'43000',
'44000',
'45000',
'46000',
'47000',
'48000',
'50000',
'51000']
이제 단순화 전처리를 한다.
아까 한번 등장한 코드다. 이번에는 단순화 계수를 직접 수동으로 지정했다. 줌 레벨 14에서 100%로 전부를 보여주었다면 한 단계 아래는 단순화 계수 5%로 지정했다. 어떤 원칙이 있는건 아니고 mapshaper 웹사이트에서 13레벨 타일이 보일 정도로 축소해놓고 계수를 드래그하면서 적절한 선을 결정했다.
layer_name = "building"
output_folder = "z:/temp/mapwork/building/"
simplification_ratio_arr = [0.001, 0.005, 0.02, 0.04, 0.05,
0.07, 0.1, 0.2, 0.3, 0.4,
0.5, 1, 2, 5, 100,]
write_fields = ['BDTYP_CD', 'BD_MGT_SN', 'GRO_FLO_CO']
for sub_folder in sub_folders:
input_file = os.path.join(source_folder, sub_folder, "TL_SPBD_BULD.shp")
target_folder = os.path.join(output_folder, sub_folder)
os.makedirs(target_folder, exist_ok=True)
print(target_folder)
for zoom_level in range(1, 13):
simplified_file = os.path.join(target_folder, f"{layer_name}_{zoom_level}.shp")
simplification_ratio = 0.01 * simplification_ratio_arr[zoom_level] # 예시로 줌 레벨에 따른 단순화 비율 설정
simplify_with_mapshaper(input_file, simplified_file, simplification_ratio,\
write_fields, 'cp949', 'utf8')
print(simplified_file)
print("Shapefiles simplified and dissolved successfully.")
서울 같은 경우 줌 레벨에 따른 단순화 결관는 아래와 같다. building_14.shp가 원본인 셈이다. 단순화 되면서 객체들도 많이 사라져서 용량이 대폭 줄어들었다.

이제 변환 후 저장하자.
__MVT_EXTENT = 8192
isIncludingLines = False
isIncludingPolygon = True
source_crs_manual = "+proj=tmerc +lat_0=38 +lon_0=127.5 +k=0.9996 +x_0=1000000 +y_0=2000000 +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +units=m +no_defs"
output_folder = "z:/temp/mapwork/building/"
tile_folder = "Z:/temp/mapwork/tiles/"
for sub_folder in sub_folders:
tiles_data = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
source_folder = os.path.join(output_folder, sub_folder)
zoom_levels = range(1,15)
print(source_folder)
process_polygon_layer("building", source_folder, zoom_levels, tiles_data,\
__MVT_EXTENT, isIncludingPolygon, isIncludingLines, source_crs_manual)
tile_dir = os.path.join(tile_folder, sub_folder)
print("타일링 끝. 저장 시작")
# 누적된 데이터를 MVT 파일로 저장
for zoom_level, tiles in tiles_data.items():
for (x_tile, y_tile), features in tiles.items():
tile_path = os.path.join(tile_dir, str(zoom_level), str(x_tile))
os.makedirs(tile_path, exist_ok=True)
mvt_path = os.path.join(tile_path, f"{y_tile}.mvt")
all_features = []
for layer_name, layer_features in features.items():
tile_layer = {
"name": layer_name,
"features": [{
#geometry와 properties이외의 필드를 넣으면
#mvt의 fields에 추가된다.
#"id" : get_layer_value(layer_name),
"geometry": feat["geometry"],
"properties": feat["properties"]
} for feat in layer_features]
}
all_features.append(tile_layer)
with open(mvt_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, \
default_options={"extents":__MVT_EXTENT,\
"y_coord_down" : False,\
"check_winding_order": True,\
"on_invalid_geometry": on_invalid_geometry_make_valid},))
print("저장 완료")
MVT_EXTENT는 기본값 4096에서 한 단계 높여 8192로 두었다.
코드는 앞에서 다룬 행정경계의 경우와 거의 같다.
단, 11110~51000 까지의 폴더를 순회하면서 작업하도록 설정했다. mvt 파일들도 17개 시도별로 17세트가 생성된다. 당연히 다시 이 17개의 폴더들을 순회하면서 하나의 mvt 파일로 merge하는 코드가 따라 붙어야 된다.
행정경계처럼 모든 중간 결과를 tiles_data 딕셔너리에 담아두고 한 번에 저장해도 이론적으로는 가능하지만, 메모리 운용 등 다소 느려질 수 있다고 판단해서 중간에 파일 시스템을 한 번 거쳐서 merge하도록 전략을 바꾸었다. merge 하는 작업은 좀 더 용량이 큰 경우나 미리 만들어 둔 여러개의 레이어 mvt들을 합칠 때 유용할 수 있다.
그런데 이런 중간 저장 과정은 예상치 못한 장점도 있었다. 막상 작업하다보니 중간에 에러가 전국 기준으로 두세번 발생했는데, 만약 변수에만 담아두었으면 중간 결과물들이 모두 사라졌을 것 같다. 오류는 도형의 토폴로지 에러때문에 발생했고, 해당 파일을 열어서 수동으로 직접 수정해주었다.
merge 하는 작업은 아래와 같이 구현했다. 소스폴더들을 배열로 받으면 그 파일들을 모두 열어서 하나로 합쳐준다. 혹시 모르니 실수로 extent가 다른 파일들을 합치지 못하도록 검증하는 부분을 두었다.
import os
import shutil
import mapbox_vector_tile
def merge(source_paths, mvt_extent, mvt_version):
featureDic = {}
for source_path in source_paths:
with open(source_path, 'rb') as f:
data = f.read()
decoded_data = mapbox_vector_tile.decode(data)
for key, value in decoded_data.items():
if key in featureDic:
if mvt_extent != value["extent"] or \
mvt_version != value["version"]:
raise ValueError(f"Error: {key}의 extent 또는 version이 일치하지 않습니다.")
featureDic[key]["features"].extend(value["features"])
else:
# featureDic에 존재하지 않는 key라면 새로운 key로 추가
featureDic[key] = {
"features": value["features"]
}
all_features = []
for layer_name, layer_features in featureDic.items():
tile_layer = {
"name": layer_name,
"features": [
{
"geometry": feature["geometry"],
"properties": feature["properties"]
} for feature in layer_features["features"]
]
}
all_features.append(tile_layer)
return all_features, mvt_extent
위의 merge 함수를 이용해 여러 폴더의 파일들을 하나로 합치는 부분은 아래와 같다.
def extract_extent_from_first_file(file_dict):
# 첫 번째 파일 경로 추출
first_file_key = next(iter(file_dict.keys()))
first_source_folder = file_dict[first_file_key][0]
first_file_path = os.path.join(first_source_folder, first_file_key)
# 파일 열고 extent 추출
with open(first_file_path, 'rb') as f:
data = f.read()
decoded_data = mapbox_vector_tile.decode(data)
# 첫 번째 레이어에서 extent 추출
first_item = next(iter(decoded_data.values()))
mvt_extent = first_item["extent"]
mvt_version = first_item["version"]
return mvt_extent, mvt_version
def merge_mvt_folders(source_folders, target_folder):
# 딕셔너리 생성
file_dict = {}
print("경로 탐색 시작")
# 모든 source_folders의 z/x/y.mvt 구조를 읽어서 딕셔너리에 저장
for source_folder in source_folders:
for root, dirs, files in os.walk(source_folder):
for file in files:
if file.endswith(".mvt"):
# 경로를 relative_path로 변환
relative_path = os.path.relpath(root, source_folder)
file_key = os.path.join(relative_path, file)
# 딕셔너리에 추가
if file_key in file_dict:
file_dict[file_key].append(source_folder)
else:
file_dict[file_key] = [source_folder]
print("경로 탐색 완료. 병합 시작")
# 첫 번째 파일에서 extent 추출
mvt_extent, mvt_version = extract_extent_from_first_file(file_dict)
print(f"Extracted extent: {mvt_extent}")
# 타겟 폴더로 파일을 병합 및 복사
i = 0
for file_key, source_folders in file_dict.items():
target_file_path = os.path.join(target_folder, file_key)
target_file_dir = os.path.dirname(target_file_path)
if (i % 2000 == 0):
print(f"{i}번째 파일 처리 중")
i += 1
# 해당 타겟 경로가 이미 존재하는지 확인
if os.path.exists(target_file_path):
# 병합 처리
source_file_paths = [os.path.join(folder, file_key) for folder in source_folders]
all_file_paths = source_file_paths + [target_file_path]
#print(source_file_paths)
all_features, mvt_extent = merge(all_file_paths, mvt_extent, mvt_version)
with open(target_file_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, \
default_options={"extents": mvt_extent, \
"on_invalid_geometry": on_invalid_geometry_make_valid}))
else:
# 폴더가 없으면 생성
if not os.path.exists(target_file_dir):
os.makedirs(target_file_dir)
source_file_paths = [os.path.join(folder, file_key) for folder in source_folders]
# source_file_paths 원소가 하나면 그냥 복사
# source_file_paths 원소가 여러개면 병합
if len(source_file_paths) == 1:
shutil.copyfile(source_file_paths[0], target_file_path)
else:
all_features, mvt_extent = merge(source_file_paths, mvt_extent, mvt_version)
with open(target_file_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, \
default_options={"extents": mvt_extent, \
"on_invalid_geometry": on_invalid_geometry_make_valid}))
먼저 입력된 폴더들을 모두 읽어서 존재하는 모든 x,y, zoom 범위를 스캔한다.
그 후에 모든 zoom, x, y, 폴더별로 파일들을 스캔하면서 합치는데, source_file_paths가 하나일 경우 굳이 merge함수를 쓰지 않고 곧바로 복사만 해 주도록 했다. 시도별로 분할된 폴더의 대부분 타일들은 하나씩만 존재하기 때문이다. 한 타일 영역 안에 두 개 이상의 시도가 포함되는 시도 경계 부분만 merge 함수 호출이 필요하다.
merge_mvt_folders 함수는 아래처럼 호출한다.
# 사용 예시
output_folder = "z:/temp/mapwork/tiles"
# 폴더 내의 모든 폴더 경로를 읽어서 리스트로 저장
source_folders = [f.path for f in os.scandir(output_folder) if f.is_dir()]
target_folder = 'z:/temp/mapwork/merged'
merge_mvt_folders(source_folders, target_folder)
이제 모든 작업이 끝났다.
빌딩 타입, 고유번호, 층 수 속성 3개만 포함한 전국 건물들의 1~14 레벨이 713MB에 모두 담겼다.
두 시간 정도면 전국 건물의 모든 타일이 생성된다. 이것마저 답답하다면 시도별 타일 생성 부분을 멀티 프로세싱으로 구현하면 된다.
시각화
deck.gl에서 구현한 결과는 아래와 같다.
deck.gl에서 terrainLayer를 이용해서 terrain과 satellite 이미지를 불러들이면 아래처럼 손쉽게 만들 수 있다. deck.gl에서는 지형 높이에 맞춰서 건물 폴리곤들을 z축으로 offset시켜주는 옵션이 있다. 건물 밑면을 지면 레벨에 맞춰준다는 말이다.
시도 경계선 같은 경우는 해당 옵션에서 "draped"로 설정하면 terrain 바로 위에 납작하게 면을 맞춰서 그려준다. 폴리곤을 변형하는게 아니라, 폴리곤을 타일 크기에 1차 렌더링 한 후 그 렌더링 결과를 텍스쳐로 terrain에 겹치는 것 같다.
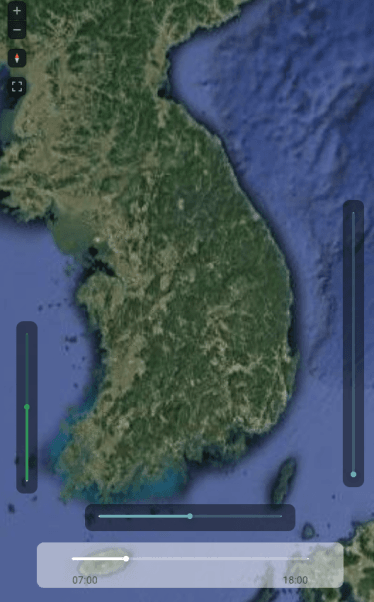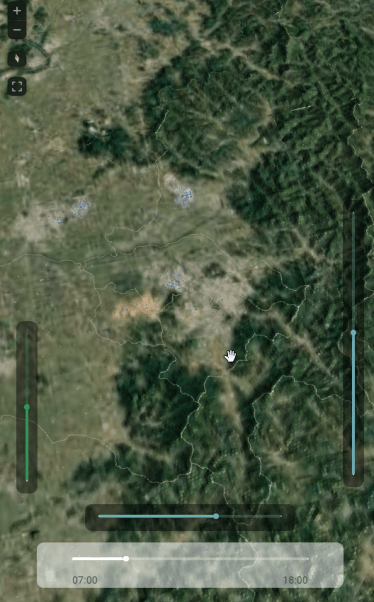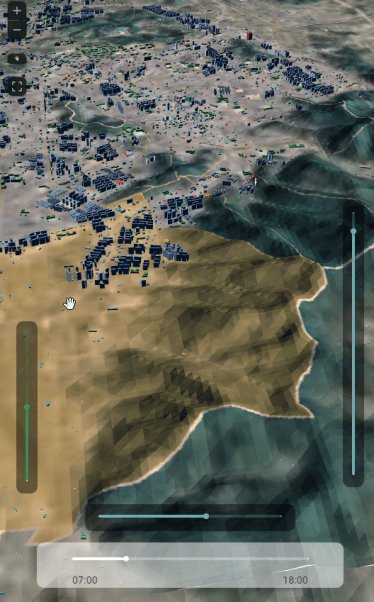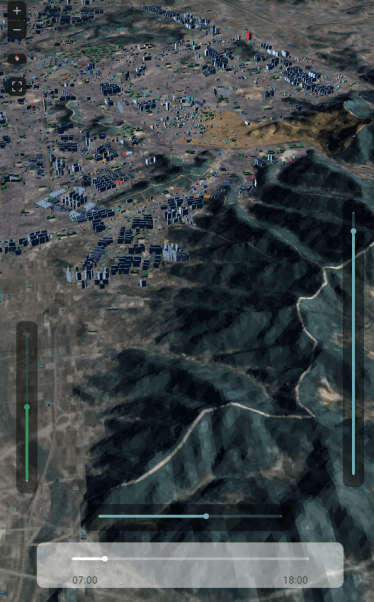
글이 좀 길어졌으므로 1부는 여기서 끝고 나머지는 2,3부에 나누어 쓰겠다.
2부는 라인과 포인트 타일링 작업,
벡터 타일 : 웹에서 대용량 공간 데이터 시각화하기 - 2
이 글에서는 라인과 포인트 데이터를 벡터 타일로 만드는 방법을 설명한다.앞서 폴리곤 먼저 진행했고, 이 글은 두 번째 글이다. 앞에서 제시한 코드들을 대부분 이용한다. 라인 shape 전처리
www.vw-lab.com
3부는 deck.gl에서 시각화 옵션 설명에 관한 내용이다.
벡터 타일 : 웹에서 대용량 공간 데이터 시각화하기 - 3
이 글은 앞서 설명한 벡터 타일맵 만들기 1,2 편에 이어지는 3편이다. 앞에서 행정동 경계 폴리곤, 전국 건물 폴리곤, 교통사고 데이터 포인트의 3개 벡터 타일을 만들었다. 이 글에서 Deck.gl의 모
www.vw-lab.com
'Function' 카테고리의 다른 글
| 벡터 타일 3 : 웹에서 대용량 공간 데이터 시각화하기 (0) | 2024.08.11 |
|---|---|
| 벡터 타일 2 : 웹에서 대용량 공간 데이터 시각화하기 (0) | 2024.08.11 |
| 벡터필드 : 웹에서 해류데이터 표현하기 (1) | 2024.02.24 |
| OD 시각화 4 : python에서 그리는 화살표 머리 이동선 (0) | 2023.08.16 |
| 서로 간섭이 덜 되어 보이는 네트워크 링크 그리기 (4) | 2023.02.24 |



