
이 글에서는 라인과 포인트 데이터를 벡터 타일로 만드는 방법을 설명한다.
앞서 폴리곤 먼저 진행했고, 이 글은 두 번째 글이다. 앞에서 제시한 코드들을 대부분 이용한다.
앞의 글은 다음의 링크에 있다.
벡터 타일 : 웹에서 대용량 공간 데이터 시각화하기 - 1
웹에서 대용량 공간 데이터를 시각화하는건 2024년이라는 시점에서 이미 새로운 기술은 아니다. 구글 맵이나 카카오 네이버 맵에서는 오래 전부터 전세계나 우리나라 전체의 지도를 브라우징하
www.vw-lab.com
라인 shape 전처리
라인 shape 파일은 LineString와 MultiLineString 으로 된 도형을 말한다.
폴리곤 처럼 단순화 작업 먼저 수행한다. 단선으로 된 도로 레이어를 작업했고, 6레벨부터 14레벨까지 만들었다.
input_file = "z:/temp/새 폴더/road.shp"
temp_folder = "z:/temp/새 폴더/temp/"
output_folder = "z:/temp/새 폴더/simplified/"
layer_name = "road"
min_zoom = 6
max_zoom = 14
os.makedirs(output_folder, exist_ok=True)
simplify_linestring(input_file, temp_folder, output_folder, layer_name, min_zoom, max_zoom)
라인 레이어는 두 단계로 단순화했다.
#라인 자체 길이를 기준으로 전처리한다.
def filter_lines_by_length(simplified_file, output_file, limit_length):
# Shapefile 읽기
reader = shapefile.Reader(simplified_file)
writer = shapefile.Writer(output_file)
writer.fields = reader.fields[1:] # 삭제 플래그 필드를 제외한 나머지 필드를 복사
for sr in reader.iterShapeRecords():
geom = shape(sr.shape.__geo_interface__)
if isinstance(geom, MultiLineString):
filtered_lines = [line for line in geom.geoms if line.length > limit_length]
if filtered_lines:
filtered_geom = MultiLineString(filtered_lines)
if filtered_geom.length > limit_length:
writer.shape(mapping(filtered_geom))
writer.record(*sr.record)
elif isinstance(geom, LineString) and geom.length > limit_length:
writer.shape(mapping(geom))
writer.record(*sr.record)
writer.close()
def simplify_linestring(input_file, temp_folder, output_folder, \
layer_name, min_zoom, max_zoom):
for zoom_level in range(min_zoom, max_zoom+1):
simplified_file = os.path.join(temp_folder, f"{layer_name}_{zoom_level}.shp")
simplification_ratio = pow(zoom_level/14,2) # 예시로 줌 레벨에 따른 단순화 비율 설정
simplify_with_mapshaper(input_file, simplified_file, simplification_ratio)
tile_size = tile_size_at_zoom(zoom_level)
limit_length = tile_size * 0.005
if zoom_level == max_zoom:
limit_length = 0
print(f'zoom : {zoom_level} : {limit_length}')
# Filter lines by length and save to output_folder
output_file = os.path.join(output_folder, f"{layer_name}_{zoom_level}.shp")
filter_lines_by_length(simplified_file, output_file, limit_length)
# Dissolve by sido, sidonm, sgg, sggnm
print("Shapefiles simplified and dissolved successfully.")
먼저 simplify_with_mapshaper로 단순화한다.
그런데 라인 레이어는 mapshaper가 폴리곤처럼 효과적으로 작업해주지는 못한다. 폴리곤들의 경우 단순화 이후 작은 도형들이 대부분 사라졌던 것에 비해 라의 경우에는 길이가 짧은 도형들이 대부분 남아 있었다.
그래서 filter_lines_by_length 라는 별도의 함수를 만들어 낮은 줌 레벨에선는 길이가 짧은 도로들을 지워주었다.
사실 이건 정말 '대충'한 전처리이고, 실제 작업에서는 도로폭인나 도로 위계등을 고려해서 줌 레벨이 낮을 때도 상위 도로 위주로 보이도록 해야한다. 우리가 흔히 지도를 볼 때 전국 레벨에서는 고속도로만 보이는 것처럼 전처리 하는 것이 일반적이다. 여튼, 낮은 줌 레벨에서 무엇을 보여줄 것인지에 대한 전처리는 전적으로 작업자의 판단에 달려 있다. 타일링 작업과는 독립적으로 이루어지지만, 낮은 줌 레벨에서 너무 상세한 도형을 많이 남기면 타일링의 의미가 사라지게 됨을 기억하자.
라인 shape 타일 작업
이제 전처리한 파일을 바탕으로 본격적인 타일링 작업을 한다. MVT_EXTENT는 기본 값인 4096으로 두었다.
layer_name = "road"
folder_name = "Z:\\temp\\새 폴더\\simplified"
zoom_levels = range(min_zoom,max_zoom+1)
tiles_data = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
__MVT_EXTENT = 4096
process_lineString_layer(layer_name, folder_name, zoom_levels, tiles_data, __MVT_EXTENT)
변환 함수는 폴리곤과 거의 똑같다.
라인의 경우 타일 경계선이 드러날 까닭이 없으니 타일 box 생성시 buffer는 0으로 두었다.
def process_lineString_layer(layer_name, folder_name, zoom_levels, tiles_data, _MVT_EXTENT):
# zoom_levels를 하나씩 순회
for zoom_level in zoom_levels:
# 사용 예제
filename = f"{folder_name}/{layer_name}_{zoom_level}.shp"
shape_records = read_and_transform_shapefile(filename)
print(f"Processing zoom level {zoom_level}, {filename}...")
buf =0
# simplified_shapes를 하나씩 순회
for geom, record in shape_records :
bounds = geom.bounds
#print(bounds)
min_tile = mercantile.tile(*projectTo4326(bounds[0], bounds[3]), zoom_level)
max_tile = mercantile.tile(*projectTo4326(bounds[2], bounds[1]), zoom_level)
# min_tile부터 max_tile까지 순회
for x_tile in range(min_tile.x, max_tile.x + 1):
for y_tile in range(min_tile.y, max_tile.y + 1):
bounds = mercantile.xy_bounds(x_tile, y_tile, zoom_level)
tile_box = Polygon([
(bounds.left-buf, bounds.bottom-buf),
(bounds.left-buf, bounds.top+buf),
(bounds.right+buf, bounds.top+buf),
(bounds.right+buf, bounds.bottom-buf),
(bounds.left-buf, bounds.bottom-buf)
])
# geom과 tile_box의 교집합 계산
intersection = tile_box.intersection(geom)
if intersection.is_empty:
continue
transformed = affinity.translate(intersection, xoff=-bounds.left, yoff=-bounds.bottom)
transformed = affinity.scale(transformed,
xfact=_MVT_EXTENT/(bounds.right-bounds.left),
yfact=_MVT_EXTENT/(bounds.top-bounds.bottom),
origin=(0, 0, 0))
serialized_linestring = {
"geometry": transformed,
"properties": record,
}
tiles_data[zoom_level][(x_tile, y_tile)][f'{layer_name}'].append(serialized_linestring)
폴리곤에서처럼 intersection을 구하고 좌표값을 0~MVT_EXTENT 범위로 바꾼 뒤 정해진 형식의 객체로 만들어 tiles_data 딕셔너리에 넣어둔다.
저장도 폴리곤과 기본적으로 동일하다.
import os
import mapbox_vector_tile
# 타일 저장 디렉토리 설정
tile_dir = "Z:/lines/public/map4/"
__MVT_EXTENT = 4096
# 누적된 데이터를 MVT 파일로 저장
for zoom_level, tiles in tiles_data.items():
for (x_tile, y_tile), features in tiles.items():
tile_path = os.path.join(tile_dir, str(zoom_level), str(x_tile))
os.makedirs(tile_path, exist_ok=True)
mvt_path = os.path.join(tile_path, f"{y_tile}.mvt")
all_features = []
for layer_name, layer_features in features.items():
tile_layer = {
"name": layer_name,
"features": [{
"geometry": feat["geometry"],
"properties": feat["properties"]
} for feat in layer_features]
}
all_features.append(tile_layer)
with open(mvt_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, \
default_options={"extents":__MVT_EXTENT, "on_invalid_geometry": on_invalid_geometry_make_valid},))
줌 레벨, x,y 타일별로 순회하면서 layer이름별로 그룹핑을 해서 mapbox_vector_tile로 인코딩하면 된다.
줌 레벨 10과 14의 결과를 비교하면 아래와 같다.
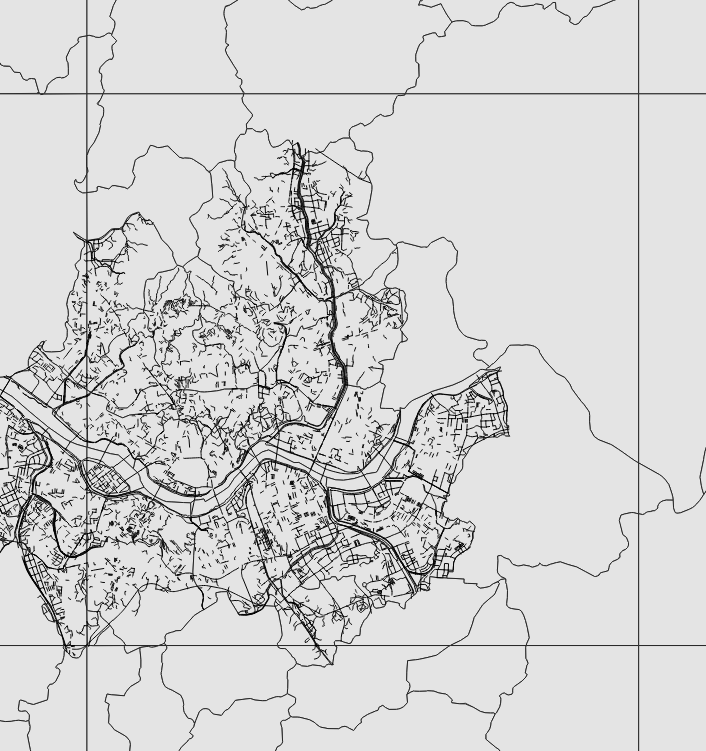

포인트 파일 타일 작업
포인트 파일은 다음의 데이터를 사용했다.
차대 사람 교통사고 데이터인데, 텍스트 기준 500MB 정도 된다. 포인트 자체는 73만개 정도에 불과하지만, 속성이 70개라서 용량이 제법 크다.
1회성 컨텐츠 웹페이지에서 모두 업로드 하기에는 터무니 없이 큰 용량이지만 타일링하게 된다면 부담 없이 얹을 수 있다.

포인트 파일은 굳이 shape 로 작업하지 않고 tsv에서 직접 처리했다.
intersection 같은 연산이 효율적으로 이루어지는지에 대한 확신이 없어서 데이터 프레임으로 한단계씩 작업했다.
layer_name = "accident"
filename = "A:\\포인트 샘플.tsv"
zoom_level = 14
xcol ="x_crdnt"
ycol = "y_crdnt"
sourceCRS = "EPSG:5179"
tiles_data = defaultdict(lambda: defaultdict(lambda: defaultdict(list)))
process_point_layer(layer_name, filename, zoom_level, xcol, ycol, sourceCRS, MVT_EXTENT, tiles_data)
전체 처리 과정이 들어간 process_point_layer는 다음과 같다.
다수의 줌 레벨을 상정하지 않고 14 단계 이상에서만 한번에 모두 드러난다고 생각했다. 만약 축소된 줌 레벨에서도 보고 싶다면 일부만 남기거나 그룹핑 해서 하나로 만드는 등의 전처리를 해주어야 한다.
def process_point_layer(layer_name, filename, zoom_level, xcol, ycol, sourceCRS, _MVT_EXTENT, tiles_data):
# 파일 읽기
df = pd.read_csv(filename, delimiter='\t')
print("df 읽음!!")
# 좌표 변환기 설정
transformer = pyproj.Transformer.from_crs(sourceCRS, "EPSG:3857", always_xy=True)
# 좌표 변환 수행
transformed_coords = df.apply(lambda row: transformer.transform(row[xcol], row[ycol]), axis=1)
# 변환된 좌표를 새로운 컬럼에 저장
df['x_3857'], df['y_3857'] = zip(*transformed_coords)
# 좌표 변환기 설정 (EPSG:3857 -> EPSG:4326)
transformer_to_4326 = pyproj.Transformer.from_crs("EPSG:3857", "EPSG:4326", always_xy=True)
# 좌표 변환 수행 (EPSG:3857 -> EPSG:4326)
transformed_coords_4326 = df.apply(lambda row: transformer_to_4326.transform(row['x_3857'], row['y_3857']), axis=1)
# 변환된 좌표를 새로운 컬럼에 저장 (EPSG:4326)
df['lon'], df['lat'] = zip(*transformed_coords_4326)
tiles = df.apply(lambda row: mercantile.tile(row['lon'], row['lat'], zoom_level), axis=1)
# 타일 번호를 새로운 컬럼에 저장
df['tile_x'] = tiles.apply(lambda t: t.x)
df['tile_y'] = tiles.apply(lambda t: t.y)
df['tile_z'] = zoom_level # 줌 레벨은 동일하므로 하나의 컬럼으로 저장
# 타일 경계값 계산 및 저장
bounds = tiles.apply(lambda t: mercantile.xy_bounds(t))
df['bnd_left'] = bounds.apply(lambda b: b[0])
df['bnd_right'] = bounds.apply(lambda b: b[2])
df['bnd_bottom'] = bounds.apply(lambda b: b[1])
df['bnd_top'] = bounds.apply(lambda b: b[3])
# 변환된 좌표 계산 및 저장
df['x_transformed'] = ((df['x_3857'] - df['bnd_left']) / (df['bnd_right'] - df['bnd_left']) * _MVT_EXTENT).astype(int)
df['y_transformed'] = ((df['y_3857'] - df['bnd_bottom']) / (df['bnd_top'] - df['bnd_bottom']) * _MVT_EXTENT).astype(int)
#변환된 좌표를 WKT 형식의 문자열로 저장
df['geometry'] = df.apply(lambda row: f"POINT ({row['x_transformed']} {row['y_transformed']})", axis=1)
# 필요한 컬럼 제외한 속성만 남기기
properties_cols = df.columns.difference(['x_3857', 'y_3857', 'tile_x', 'tile_y', 'tile_z', 'bnd_left', 'bnd_right', 'bnd_top', 'bnd_bottom', 'x_transformed', 'y_transformed', 'geometry'])
# 타일 번호로 데이터 그룹핑
grouped = df.groupby(['tile_z', 'tile_x', 'tile_y'])
print("처리 완료. 변수에 저장 시작")
for (z, x, y), group in grouped:
if z not in tiles_data:
tiles_data[z] = {}
if (x, y) not in tiles_data[z]:
tiles_data[z][(x, y)] = {}
tiles_data[z][(x, y)][layer_name] = [{
"geometry": row['geometry'],
"properties": row[properties_cols].to_dict()
} for _, row in group.iterrows()]
print("끝")
코드는 길지만 진행 과정은 단순하다.
1. 좌표계를 EPSG3857로 변환한다. 이하 모든 작업은 데이터 프레임에서 row별로 이루어진다.
2. mercantile 라이브러리를 사용하기 위해 4326으로도 변환한다.
3. 타일 번호와 타일 경계값을 계산한다.
4. 좌표를 0~MVT_EXTENT안의 값으로 변환하여 WKT 형식의 문자열( POINT (x y) )로 바꾼다.
5. 중간 단계의 컬럼들은 필터링해서 삭제하고 좌표값과 나머지 속성들을 남겨서 tiles_data에 담는다.
각각의 점 하나하나가 어느 타일에 속할지 계산할 수 있으므로 굳이 intersect 연산을 하지 않고 점 단위(row 단위)로 계산했다.
포인트 파일 저장
# 타일 데이터 저장
layer_name = "accident"
tile_dir = f"Z:/temp/public/{layer_name}/"
__MVT_EXTENT = 4096
for zoom_level, tiles in tiles_data.items():
for (x_tile, y_tile), features in tiles.items():
tile_path = os.path.join(tile_dir, str(zoom_level), str(x_tile))
os.makedirs(tile_path, exist_ok=True)
mvt_path = os.path.join(tile_path, f"{y_tile}.mvt")
all_features = []
for layer_name, layer_features in features.items():
tile_layer = {
"name": layer_name,
"features": [{
"geometry": feat["geometry"],
"properties": feat["properties"]
} for feat in layer_features]
}
all_features.append(tile_layer)
with open(mvt_path, 'wb') as f:
f.write(mapbox_vector_tile.encode(all_features, default_options={"extents": __MVT_EXTENT}))
저장 역시 라인이나 폴리곤과 거의 동일하다. 중복되는 설명은 생략한다.
결과는 다음과 같이 만들어졌다. 14레벨 타일에 데이터가 집중된 정도에 따라 용량이 차이나지만 70개나 되는 속성을 모두 담아도, 특정 영역들만 브라우징 하면서 데이터를 받아내기에는 부담스런 용량이 아니다.
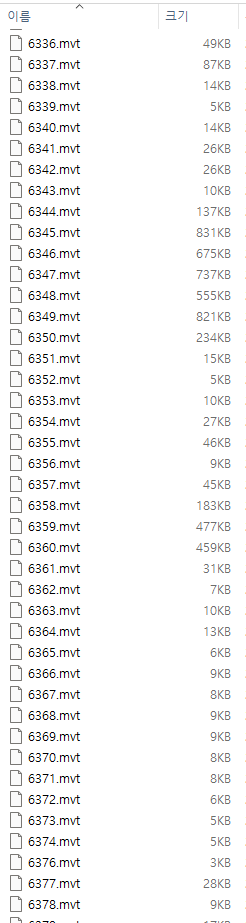
mvt가 바이너리로 자체 압축되어 있기 때문에 전체 용량은 500메가에서 340메가로 줄어들었다. 담는 내용은 동일하다.
deck.gl에서 시각화한 결과는 아래와 같다.

폴리곤 포함 전체 코드는 아래 첨부한 파이썬 노트북 파일에 담았다.
그럼 이제 마지막으로 deck.gl에서 mvtLayer 다루는 법을 알아보자.
벡터 타일 : 웹에서 대용량 공간 데이터 시각화하기 - 3
이 글은 앞서 설명한 벡터 타일맵 만들기 1,2 편에 이어지는 3편이다. 앞에서 행정동 경계 폴리곤, 전국 건물 폴리곤, 교통사고 데이터 포인트의 3개 벡터 타일을 만들었다. 이 글에서 Deck.gl의 모
www.vw-lab.com
'Function' 카테고리의 다른 글
| deck.gl로 만든 웹 지도의 hillshade 표현 (0) | 2024.10.28 |
|---|---|
| 벡터 타일 3 : 웹에서 대용량 공간 데이터 시각화하기 (0) | 2024.08.11 |
| 벡터 타일 1 : 웹에서 대용량 공간 데이터 시각화하기 (0) | 2024.08.11 |
| 벡터필드 : 웹에서 해류데이터 표현하기 (1) | 2024.02.24 |
| OD 시각화 4 : python에서 그리는 화살표 머리 이동선 (0) | 2023.08.16 |



